It’s that time of year again. Just like last year, I’m going to use the week after re:Invent to binge on recorded sessions at 1.5X speed, and share my thoughts with you.

All the sessions are recorded with high quality audio/video and available via both the AWS web site and YouTube.
If you’re looking for a comprehensive list of all the new announcements, then head over to the AWS News Blog.
Keynotes
Peter DeSantis - SVP AWS
The “Monday Night Live tradition of diving deep into the engineering that powers AWS services”. This time focus is on Aurora Limitless, Elasticache Serverless, Redshift Serverless and Quantum Computing research.
- Why serverless is great
- More elastic
- Pay only for what you use
- More sustainable
- More secure
- Why isn’t everything serverless?
- Customers wary of the new
- Less capable than traditional services in the beginning
- AWS do whatever customers ask
- Making it easier to use traditional serverfull services like relational databases
- RDS makes it easier
- Then Aurora which is effectively built on serverless storage layer (“Grover”)
- Aurora serverless gives you auto scaling of the database engine instances (but still running on dedicated instances)
- Nitro hypervisor to securely divide physical hardware into instances. Rigid boundaries.
- Caspian is new hypervisor for databases. Able to dynamically scale memory up and down depending on load.
- If physical hardware runs out of memory, Caspian tells DB no more memory is available and migrates it to another physical instance.
- Prediction system to make sure more resources are available
- Still have upper limit of fixed number of instances at maximum size. Need to shard DB to go beyond. Which is hard for application to implement.
- Announcing Aurora Limitless Database.
- Automatically distributes data across multiple shards
- Provides transactional consistency across shards
- Lightweight routing layer - just enough metadata to be able to route
- All shards are elastic, running on Caspian.
- Grover makes it easy to split shard by duplicating then using Caspian to scale down.
- Needs distributed timekeeping for cross-shard transactions.
- Rather than using single timekeeper or logical clocks, uses AWS Time Sync service to ensure all system clocks within millisecond.
- Limits number of ordered transactions you can have.
- Latest versions of Nitro have dedicated hardware that interacts with rack local reference clock that in turn is connected to dedicated time distribution hardware synced with an atomic clock. All in hardware. Can sync clocks within some number of nanoseconds.
- Same system accessible to customers through new version of AWS Time Sync which provides accurate time with sub-microsecond latency.
- Means Aurora limitless can have hundreds of thousands of ordered events per second.
- AWS ElastiCache
- Currently not serverless
- Have to specify a server instance to run it on
- Announcing Amazon ElastiCache Serverless
- Redit 7 and Memcached 1.6 compatible
- p50 latency of 500 us, p99 of 1.2ms
- Supports up to 5TB memory
- Uses same Caspian/Grover shards as Aurora with a low latency, predictable routing layer in front of it
- Customer story from Riot games, migrating League of Legends to AWS
- Need to update simulation state 128 times a second to make first person shooter fair
- Migrated 14 data centers to AWS
- Needed AWS to version of EKS which could guarantee container would stay up for 35 minutes (length of game)
- AWS Redshift Serverless
- Issues with interference between queries. Large ETL query can crowd out small ad-hoc realtime queries.
- Previously scaled based on query volume, time to spin up new capacity, doesn’t work well for mixed size workloads
- Announcing Next-generation AI based scaling
- ML forecasting model for capacity needed
- Separate ML model to predict resource requirements of each query
- Locally trained query that understands your queries, fallback to bigger globally trained model for more complex queries
- Needs to understand how queries will respond to more resoures (superlinear, linear or sublinear)
- Intelligent query manager which decides how to best schedule queries using available resources
- Quantum Computing
- Quick history of quantum computing
- Need many thousands of qubits to do anything useful
- Quantum computers are hard to scale because of errors introduced by noise - phase flips as well as bit flips
- State of art is 1 error per 1000 quantum operations
- Need 1 error in billions of operations
- Can do error correction but then need 1000s of physical qubits for each logical. Currently need millions for interesting algorithms.
- AWS quantum team using new hardware error correction system with 6X improvement
Adam Selipsky - CEO AWS
AWS CEO “shares his perspective on cloud transformation”. “Highlighting innovation in data, infrastructure, AI and ML”.
Apart from the S3 Express One Zone and zero ETL announcements, this is dominated by AI and in particular AWS playing catch up with OpenAI.
- Partnership with Salesforce
- 80% of “unicorn” startups on AWS
- Segways into the standard AWS pitch
- Announcing AWS S3 Express One Zone
- Highest performance and lowest latency cloud storage
- Designed for low latency workloads that can tolerate lower durability (e.g. caching, ML training)
- Data is stored in single customer selected AZ (colocate with your compute)
- Single-digit millisecond latency
- Millions of requests per minute (which is a weird metric, guess requests per second number wasn’t impressive enough)
- 50% lower access costs vs S3 standard
- Announcing AWS Graviton 4
- 50% more cores, 30% faster, more efficient
- R8g is first Graviton 4 instance
- Generative AI
- AI stack: training and running models, tools to work with standard foundation models, applications that leverage FMs
- Training and running models
- Partnership with NVIDIA, always first with latest NVIDIA chips
- EC2 ultra clusters - up to 20K GPUs
- Jenson Huang (with his trademark leather jacket), live on stage
- Two million GPUs on AWS already
- Announcing availability of three new GPUs on AWS plus all NVIDIA’s software stacks and libraries
- GH200 chips have GPU + ARM core on same chip with 1TB/s interconnect
- Announcing DGX cloud on AWS. DGX cloud is tool that NVIDIA’s AI teams use internally for training.
- EC2 Capacity blocks for ML - reserve EC2 ultra blocks for short term use
- Announcing AWS Trainium 2
- 4X faster for Trainium 1 chips
- AWS Neuron SDK to use standard frameworks on Trainium
- Tools to work with standard foundation models
- AWS bedrock - choice of industry standard FMs
- Partnership with Anthropic - Dario Amodei live on stage
- Range of AWS Titan FMs
- Bedrock allows you to fine tune Titan FMs based on your own data
- Retrieval Augmented Generation (RAG) - using additional data that model wasn’t trained on. Now in GA.
- Continuous pre-training - customizing FM using unlabelled data
- Agents for Bedrock now in GA. Combines FM + prompts + Lambda to let AI execute tasks (scary!)
- Bedrock security - no customer data used to train shared foundation model, fine tuned model private to you.
- Announcing Guardrails for Bedrock - specify responsible AI policies for your applications
- Pfizer customer story
- Top level of stack
- Free AI/ML training, commitment to train 25 million people
- CodeWhisperer code suggestions free for individual use
- CodeWhisperer Customization using your own code (private to you)
- Announcing Amazon Q generative AI powered assistant
- Understands user’s role and access to information, prevents access to information you shouldn’t have access to
- Integrated into console and AWS marketing site (lots of third party reports that Q is not as accurate as it should be)
- Amazon CodeCatalyst Q integration to plan and automate feature development lifecycle
- Amazon Q Code Transformation - upgrade code, remove deprecated code, apply security best practices. Only available on Java so far.
- Amazon Q as business expert - integrations with 40 enterprise applications
- Connect to data sources, index them, generate semantic understanding
- Answers include references to sources
- Supports queries on ad-hoc data by uploading documents
- Amazon Q in AWS QuickSight to tailor dashboard and generate reports based on your prompts
- Amazon Q in AWS Connect call center system
- BMW customer story
- “Your data is your differentiator”
- Cloud data services: S3, relational databases, special purpose databases, analytics, AI training
- Integration using painful ETL process
- Vision of zero ETL future
- Last year had Aurora MySQL-RedShift zero ETL integration
- Announcing Aurora PostgresSQL, RDS MySQL, DynamoDB zero ETL integrations with Redshift
- Announcing DynamoDB zero ETL integration with OpenSearch
- Amazon DataZone to populate and maintain a data catalog
- Announcing Amazon DataZone AI Recommendations to add more automation to the process
- Project Kuiper internet satellites. Announcing Kuiper Private Connectivity Services, direct link style connection from customer to AWS via Kuiper
Dr. Swami Sivasubramanian - VP Data & AI
This is an extended version of the AI and Data section in Adam Selipsky’s keynote. All the same announcements with more context, background and customer stories. No point watching both. Pick whether you want the short or long version. I only took one additional bullet point.
- Latest versions of Foundational Models have 50% less hallucinations!
Dr. Werner Vogels - CTO Amazon.com
All about architecting for cost with a few developer focused announcements sprinkled in. Not as thought provoking as last year but still worth a watch.
- Cloud removed constraint of working with finite hardware resources
- Lost the art of architecting for cost - that’s what this talk will focus on
- PBS moved to the cloud and rearchitected achieving 80% savings
- Cost is a good proxy for sustainability
- Book - “The Frugal Architect”
- Design
- Cost is a non-functional requirement (like security, compliance, accessibility)
- AWS price model follows their costs
- Three basic dimensions: bytes stored, bytes transferred, number of requests
- When you figure out your app’s pricing model need to do the same thing
- “Systems that last align cost to business value”
- “Find the dimension that you’re going to make money over, then make sure your architecture follows the money”
- Align cost and revenue
- Example of uncapped data plan leading telecoms company to bankruptcy
- If you get it right, cost as proportion of revenue goes down as you scale up (economies of scale)
- Early days of Lambda built on architecture that wasn’t cost effective (dedicated EC2 instances per customer). Did it to gain insight on customer requirements. In parallel started greenfield project to do it properly which became Firecracker microVM.
- Build evolvable architectures (Lambda transitioned to Firecracker without customer impact)
- You need to pay off your technical debt
- Customer story: Nubank
- Every engineering decision is a buying decision
- Align your priorities
- Measure
- Understand what you’re measuring and how it can change behavior
- Amazon.com measures cost per request at microservice level and aggregates cost of overall experience on the website
- Try to drive down cost per request over time
- Diminishing returns
- Measure impact of new features, stop investing if extra costs don’t drive extra revenue
- Announcing AWS Management Console myApplications
- Tag resources by application and get metrics broken out for you
- Announcing AWS CloudWatch Application Signals
- Auto-setup of key metrics dashboard for your EKS application
- Unobserved systems lead to unknown costs
- Cost-aware architectures implement cost controls
- Ability to turn off features if exceeding cost limits - in partnership with business
- Amazon.com has tiers of features depending on importance (e.g. checkout is in tier 1). Use tiers to determine what gets throttled back in case of incident or cost controls exceeeded.
- Optimize
- Cost optimization is incremental
- Eliminate digital waste: Stop, Rightsize, Shift, Reduce
- AWS CodeGuru Profiler - continually understand where your cycles are going
- Unchallenged success leads to bad assumptions - “we’ve always done it this way”
- Cost to build much smaller than cost to operate
- Paper looking at Energy Efficiency of programming languages. Ruby/Python 60 times more expensive than Rust/C++. Interestingly JavaScript only 5 times more expensive.
- Use fast prototyping to disconfirm your beliefs
- Constraints breed creativity
- To predict the future, observe the present
- Originally AI was top down, symbolic reasoning. Over last 15 years shifted to bottom up, computer vision, then deep learning.
- Don’t have to jump on the generative AI hype train. Lots of examples of success using “good old fashioned AI”.
- Werner’s personal project - looking for something he could do using ML for radiology. After all, has been telling us how easy it is to integrate ML.
- Trying to recognize signs of brain hemorrhage in CT scans
- Already a public labelled set of brain scans available for training
- Used standard Python frameworks to train a model, running on SageMaker
- Used CodeWhisperer to speed up getting something working
- Built app around the model using Lambda and AWS Amplify
- Cleaned up sample available on GitHub
- “If I can do it, you can do it”
- Needs to be small, fast, inexpensive. Ideally run locally.
- Generative AI CDK Constructs also on Github
- Announcing Amazon SageMaker Studio Code Editor
- Integrated open source version of VS Code
- Using Amazon Q to empower developers
- Ask it about appropriate AWS services - there’s too many to keep track of
- Integrated into CodeCatalyst - great way to learn a new area
- Integrated into IDE
- Announcing AWS Application Composer in VS Code
- Visually compose infrastructure as code directly in VS Code, see changes reflected in code
- Amazon Q also integrated
Innovation Talks
New category of talk at Re:Invent. I dipped into a couple. Seems to be AWS VPs talking at a very high level about their area of responsibility. Like mini-keynotes but without the production values and new announcements.
I gave up and moved onto the breakout sessions
Breakout Sessions
At time of writing breakdown sessions were “coming soon” on the AWS on-demand site, but were all uploaded to YouTube. Being presented with a playlist of 655 videos makes it hard to find what’s worth watching. This is my random sampling, concentrating on 300 and 400 level sessions on new announcements.
Introducing Amazon ElastiCache Serverless
A great technical accomplishment, much better than original ElastiCache, but not truly serverless. Still need a VPC and storage charge is for a minimum of 1 GB per cache (which is $90 per month).
- Intro stuff: What is caching, what is Redis, what is memcached
- Capacity planning for ElastiCache is hard. How do you choose appropriate instance size?
- Monitoring and adjusting capacity up and down is hard
- High availability for memcached is hard - client has to handle everything
- Already supported auto-scaling rules for scale up and down
- ElastiCache does it all for you
- No choosing instance size
- No capacity management needed
- Create a cache in under a minute
- 700 microseconds p50, 1300 microseconds p99 latency reads
- 1100 microseconds p50, 1900 microseconds p99 latency writes
- Millions of requests/second
- Pay per use pricing
- 99.99% availability SLA
- Single endpoint
- Up to 5 TB of storage
- Deployed to two AZs in your VPC (not true serverless if you need a VPC?)
- Scales vertically and horizontally based on memory/compute/network use
- Pricing based on data stored in GB-hours and request processing in ElastiCache Processing Units (ECPUs)
- ECPUs are fine grained. Depend on Redis/Memcached commands used. At simplest Redis get/set commands use 1 ECPU per KB transferred.
- More complex commands are charged based on resources consumed compared to baseline of get/set commands
- Encryption at rest always on
- Automatic software updates and backups
- Single endpoint - client has no visibility of cluster topology, no reconnect on node failure or scaling
- How it works
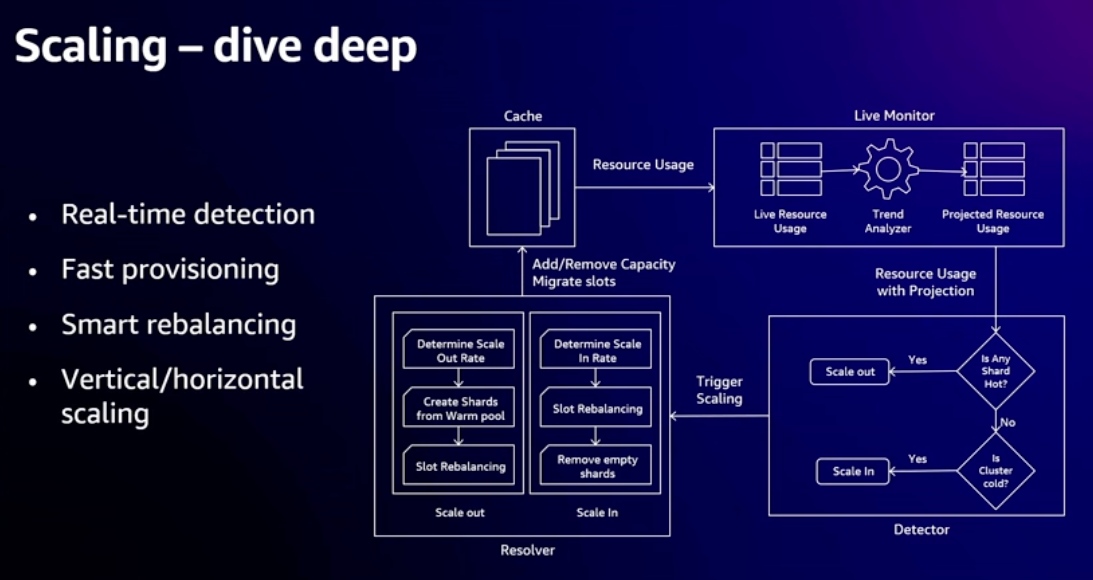
- Scales when 50% usage of any resource reached, to ensure it can handle spikes up to 2X current load
- Lots of optimizations to speed up process of migrating shards
- Built on Caspian platform - instant in place scale up of EC2 instances (if resources available on physical host)
- Noisy neighbor isolation
- Each shard has a primary and a replica
- New proxy layer to provide single endpoint, high availability, written in Rust
- Multiplex multiple requests into single network request to cache engine for better throughput
- Engine and proxy nodes deployed to multiple AZs, clients in customer VPC routed to AZ-local proxy
- Read from replica if needed to stay in local AZ
Achieving scale with Amazon Aurora Limitless Database
If you ever scale a service beyond what a single database cluster can handle, you’ll know how painful implementing sharding can be. In principle, Aurora Limitless should make it simple, especially for cases like sharding by tenant in a multi-tenant SaaS application. However, there’s a lot going on behind the scenes with deep changes to Postgres internals. Make sure you test your use case well before going all in.
- Scaling beyond what a single instance can happen
- Ultimately have to scale horizontally
- Easier for reads - add more replicas
- Single master instance is bottleneck for writes
- Solution is sharding but adds lots of complexity on application side
- Limited preview for Postgres flavor of Aurora
- Serverless deployment with distributed architecture accessed through single interface
- Transactionally consistent
- Scales to petabytes of data
- Application needs to identify a column in each table to use as a shard key
- Data from tables with same shard key can be co-located on same physical instance for improved performance
- Reference tables can be duplicated across all shards
- Rather than extending SQL syntax to create sharded table, use aurora session parameters to enable shared mode and define shard key that subsequent create table statement will use. Bit clunky?
- Additional session parameter to specify that next table created should be colocated with existing table
- Similarly, there’s another setting that will make the next table created a reference table
- Limitless database adds concept of a shard group to the existing Aurora architecture
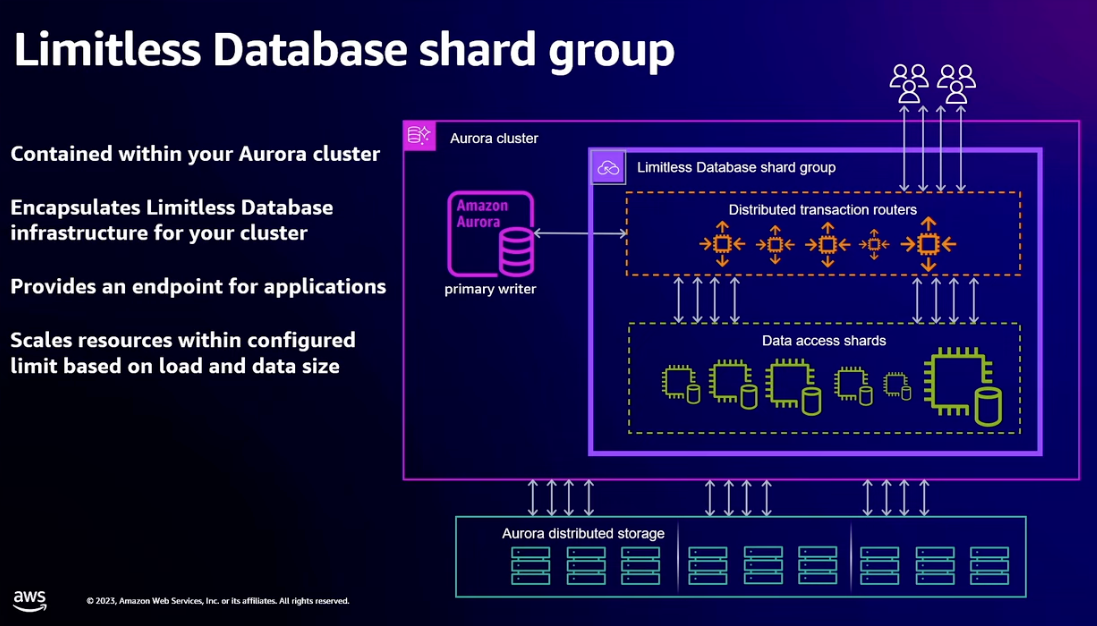
- New endpoint that resolves to transaction routers
- Serve all application traffic to sharded tables
- Scale vertically and horizontally based on load
- Routers know schema and key range placement
- Assign time for transaction snapshot and drive distributed commits
- Perform initial query planning and aggregate results from multi-shard queries
- Data access shards
- Own portion of sharded table key space and have full copies of reference tables
- Scale vertically and then split based on load
- Perform local planning and execution of query fragments
- Execute local transaction logic
- Backed by Aurora distributed storage
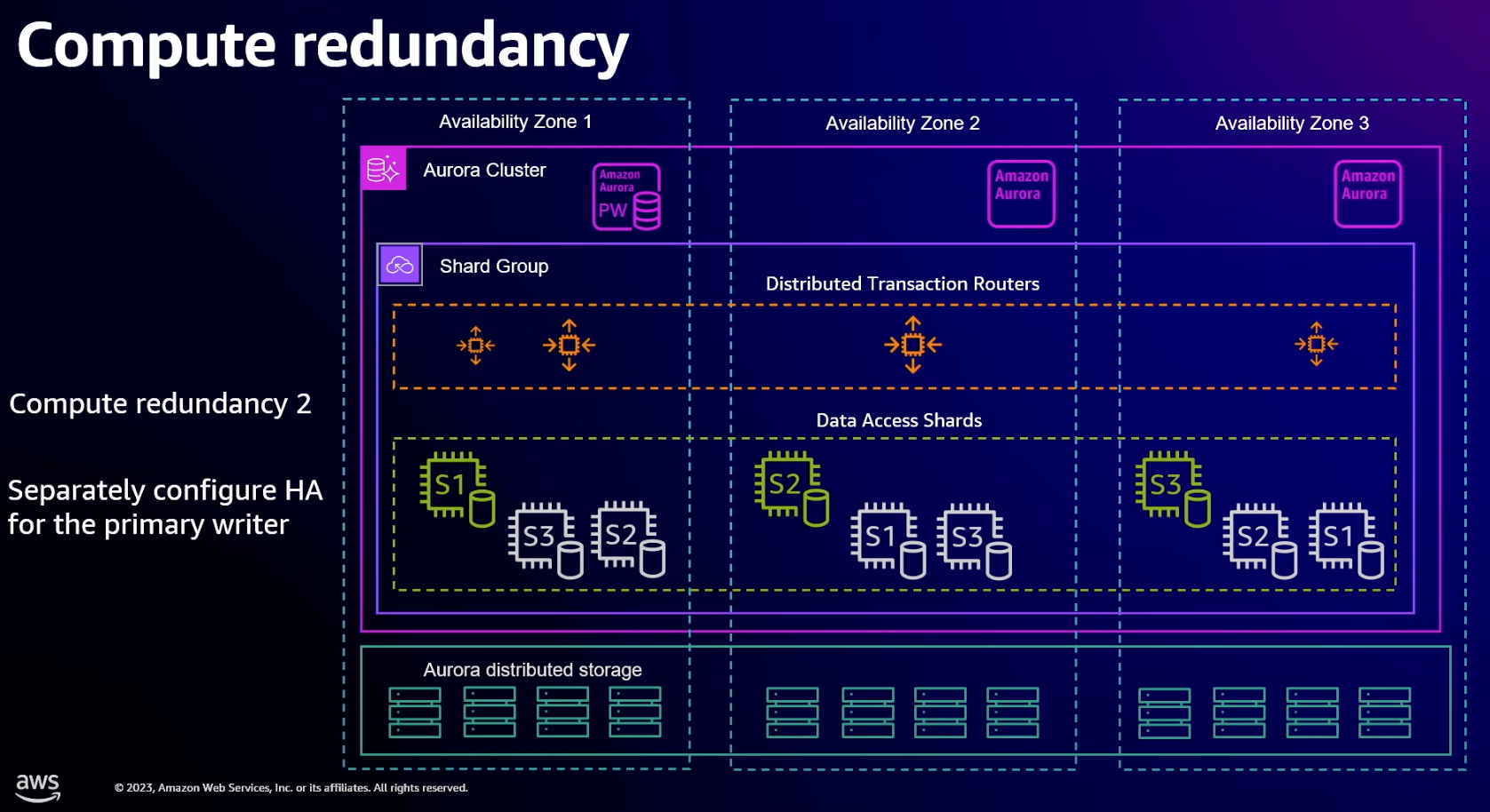
- When creating a shard group you specify max number of ACUs you want the shard group to scale to and the level of compute redundancy
- Compute redundancy controls level of HA for data access shards. This is compute only, no persistent data.
- Level 0 has everything spread across multiple AZs. If shard fails it needs to be restarted and get back up to speed which will take some time.
- Level 1 adds one redundant copy of each shard in another AZ
- Level 2 adds two redundant copies in another two AZs
- Also need to configure failover instances for the standard database primary writer (which is outside shard group)
- Hash-range partitioning
- Shard key hashed to 64-bits
- Ranges of 64-bit space are assigned to shards
- From example, looks like this ties into Postgres’s existing table partitioning feature
- Shards are all in sync and strongly consistent - no change to Postgres semantics
- Internally (not visible to user), table fragments are partitioned into sub-range slices to improve intra-shard parallelism and to make it easy to repartition on horizontal scale out
- Leveraging Aurora storage layer to duplicate and move table slices around
- Reference table updates are strongly consistent. Intended to enable join pushdown for infrequently written tables
- Supports READ COMMITTED and REPEATABLE READ transaction levels with same consistency as in a single system
- Distributed transactions built on bounded clocks
- Using EC2 TimeSync have an approximate current time and an earliest and latest possible time which bound actual time
- Enhanced Postgres to store (earliest,current,latest) tuple with each transaction
- Updated commit logic so that commit won’t complete until full time range is in the past, so no possibility of a conflicting update arriving after commit with an earlier timestamp due to clock skew
- Provides global read-after-write, one phase local commit, two phase distributed commit
- Overall
- Same RC/RR semantics as single instance Postgres (what about serialized isolation?)
- All reads are consistent without having to use a quorum, even on failover
- Commits within a single shard scale linearly (millions per second)
- Distributed commits are slower, using two phase commit, but still atomic
- SQL compatibility
- Postgres wire compatible
- Postgres SQL parser and semantics
- “Broad coverage” of feature set with selected extensions
- Implemented using a custom foreign data wrapper
- Optimized fast path for single shard cases
- Sharding system exposed through Postgres EXPLAIN so you can tune queries appropriately
- Lots of embarrassingly parallel operations that just run faster
- Create index, Analyze, Vacuum, Aggregates (sum, min, max, etc)
Deep dive on Amazon S3 Express One Zone storage class
New S3 storage class where everything is stored in a single AZ. Could be interesting for some use cases. Not clear how it works with Lambda as there’s no direct way of specifying which AZ the lambda instances should be deployed to. You can do it indirectly by connecting the Lambda to a VPC and then mapping the subnet to only one AZ. However, then not truly serverless due to fixed cost of VPC.
- S3 scales to trillions of objects and millions of requests per second
- Some applications need to reduce access latency, or end up building custom caching systems
- S3 Express One Zone is for them
- Single-digit millisecond consistent first byte latency
- Millions of requests per minute
- 10X faster than S3 standard
- Built differently
- One AZ architecture enabling co-location with compute
- New S3 directory bucket type to enable high transaction workloads
- Session-based access for faster authorization
- One Zone architecture
- Still have 3 redundant copies but now they’re all in the same AZ
- Co-locating compute reduces latency but doesn’t change cost. Standard S3 doesn’t charge for inter-AZ transfers, so you’re not saving any money by avoiding them.
- Change in durability model - no longer resilient to failures which take out the entire AZ.
- S3 directory buckets
- Rather than scaling incrementally under load, scales in large chunks
- New security model
- CreateSession API
- Returns a session token to include in all your requests
- Grants access to the bucket
- Token can be either ReadOnly or ReadWrite
- Single-step batch operations to move data from regular S3 bucket to S3 One Zone
- Integration with other AWS services
- CloudWatch
- VPC/IAM
- EMR/Athena
- SageMaker
- EKS/EC2/Lambda
- SDKs and other developer tools
- Performance gains - typical pattern is to move data from standard S3 to One Zone before running job against it
- Athena 2.1X faster with 50% lower request costs
- EMR 4X faster
- SageMaker 5.8X faster
- Improved GPU usage for ML training jobs due to lower more consistency latency, less blocking waits
- Mountpoint for S3 6X faster
- Live side by side performance tests showing One Zone is indeed much faster than regular S3
- Customer case study: Pinterest
Best practices for querying vector data for gen AI apps in PostgresSQL
The keynotes had mentioned database extensions to store vector data for generative AI. Not something I was aware of and was keen to find out more.
- Generational AI is powered by foundation models
- Can be augmented with additional data - retrieval augmented generation
- For example, a knowledge base in a database
- Need a common interface to take text, image, video, whatever data and make it accessible to the foundational model
- Which is where vectors come in
- Uses an “embedding model” to convert raw data to vector
- Core workflow is performing similarity searches on vectors
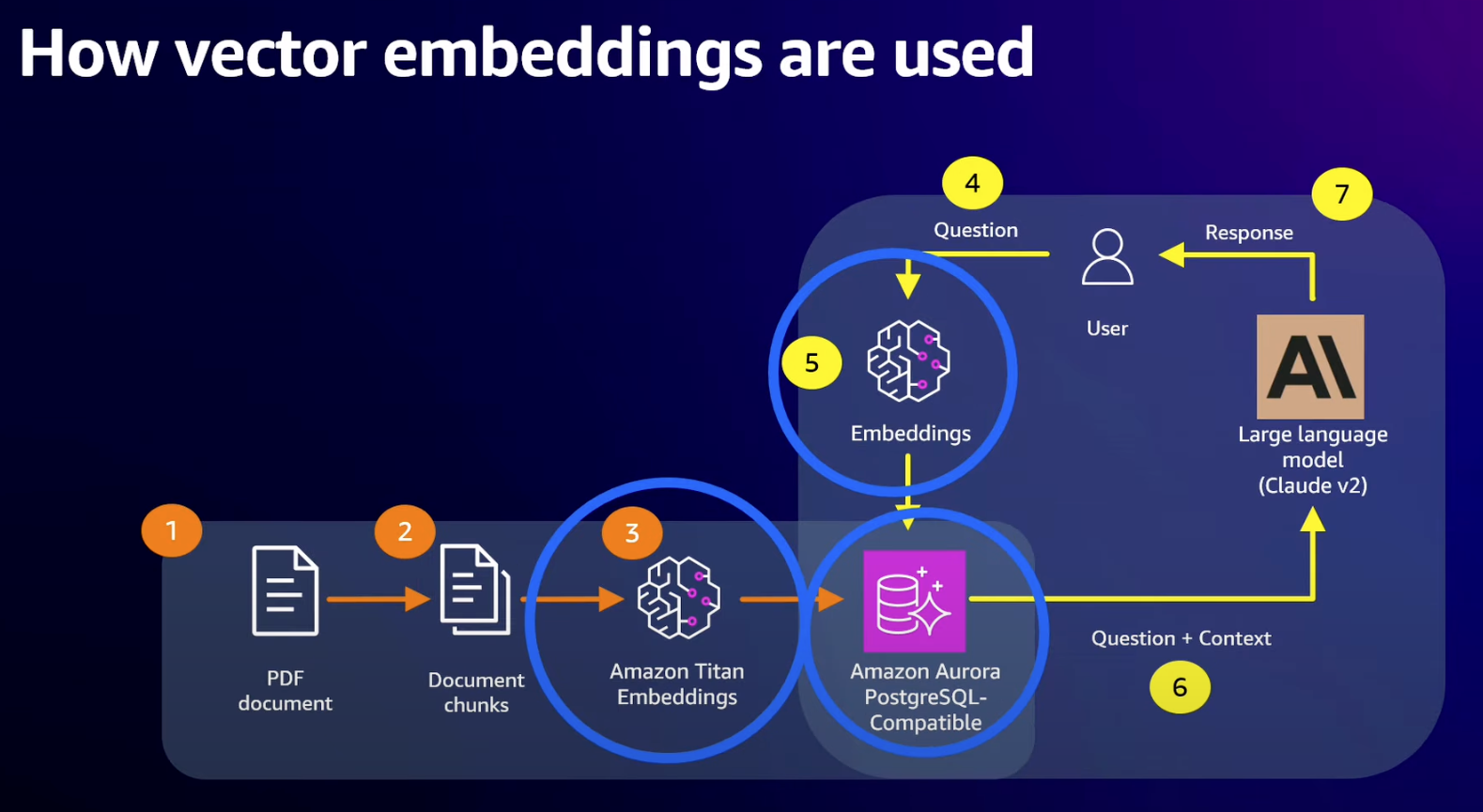
- Vectors used typically have large dimensions dependent on embedding model
- Titan embeddings uses 1536 dimensions with a 4 byte float for each value which is 6KB per vector
- If your knowledge base is large, can have millions of vectors to generate and store
- Vectors are hard to compress
- Queries use distance operations on vectors which need to query every element in the vector, for every vector in the set
- Use Approximate Nearest Neighbour (ANN) to speed things up
- Need to keep in mind that queries are approximate - can trade off accuracy (aka “recall”) vs cost and speed
- Lots of choices for vector storage system depending on scale - in memory, database, S3
- Why use PostgreSQL
- Existing client libraries
- Convenient to co-locate app and AI data
- Access to transactions and all the other relational database features
- pgvector is an open source extension for Postgres that adds support for storage, indexing, searching, metadata with choice of distance vector data type
- IVFFlat and HNSW indexing
- Exact K nearest neighbour and ANN
- IVFFlat
- Inverted flat file
- Organizes vectors into lists
- Needs to be prebuilt (determine lists and how to map vectors to lists up front)
- Insert time bounded by number of lists
- HNSW
- Graph based
- Navigate down into neighbourhood where vectors are most similar to what you’re looking for
- Iterative insertion
- Insertion time increases as size of graph increases
- Which index to use?
- If you need exact results, no index. Search over everything.
- IVFFlat is fast, HNSW is easy to manage
- Best Practices
- By default vectors are so large that Postgres will tstore as TOAST (out of line from main pages) and compressed
- Will get better results by turning off compression and in most cases turning off TOAST
- Lots of detailed guidance on tuning HNSW and IVFFlat index parameters
- HNSW needs more work up front to build index but has best query performance
- Use concurrent inserts starting from empty table to speed up building HNSW index
- Be careful using filtering - may not use index
- Consider using partial indexing to build index on pre-filtered values
- Consider partitioning table and building indexes on specific partitions
- Aurora features for vector workloads
- Optimized reads - NVMe caching of otherwise evicted pages
- When working set exceeds memory can get up to 9X speed up from Aurora caching
- Graviton3 significantly faster than Graviton2
Amazon DynamoDB zero-ETL integration with Amazon OpenSearch Service
Existing commonly used integration pattern managed for you. No new functionality needed in DynamoDB or OpenSearch.
- Example data set of Amazon.com product questions
- How to set it up for OpenSearch integration
- Design schema in usual way thinking about access patterns - single table design
- Now PM wants to add search features …
- Classic OpenSearch integration is export snapshot to S3, ingest into OpenSearch. Use DynamoDB streams with Lambda to incrementally update OpenSearch
- Zero ETL integration basically does that for you
- OpenSearch ingestion powered by DataPrepper - rich set of processors to manipulate data for OpenSearch
- Walk through using console to set up and configure. DataPrepper config files to describe how to map the data
- Use whatever version of OpenSearch you like as a target
- Table in DynamoDB maps to index in OpenSearch
- Item in DynamoDB maps to document in OpenSearch
- OpenSearch indexes have a schema. DynamoDB attributes map to fields in OpenSearch index. Schema defines types for each field.
- Avoid relying on dynamic mapping (OpenSearch guesses types for you)
- Can’t change schema later without rebuilding the index from scratch
- Best Practices
- Make use of DataPrepper pipelines
- Consider routing different item types in a single table to different indexes
- Enable CloudWatch logs for ingestion pipeline
- Always use a “dead letter queue”
- To recreate; stop the pipeline, delete and recreate index, then restart pipeline
- Add S3 as a second sink to capture transformed documents being ingested which you can use to find problems / debug
- Rule of thumb for OpenSearch capacity
- Each OCU can support about 5MB/s ingestion rate (YMMV)
- Allow 1 OCU per 5000 DynamoDB WCU
SaaS Anywhere: Designing distributed multi-tenant architectures
High level overview of how you can let your customers own and control some of the infrastructure for their own tenant.
- SaaS Anywhere: Architecture model where part of your system’s resources are hosted in a remote environment that may not be under the control of the SaaS provider
- Typically some or all of data plane infrastructure is owned and managed by your customer/tenant
- Implies per tenant infrastructure resources - not getting economies of multiple tenants sharing a resource
- Patterns and strategies to create multi-tenant solutions that support centralized provisioning, configuration, operation and deployment of remote application resources
- Design considerations
- Availability and Reliability: Shared responsbility model between SaaS provider and tenant
- Frictionless onboarding: Can you achieve anything close to self service sign up of fully managed SaaS?
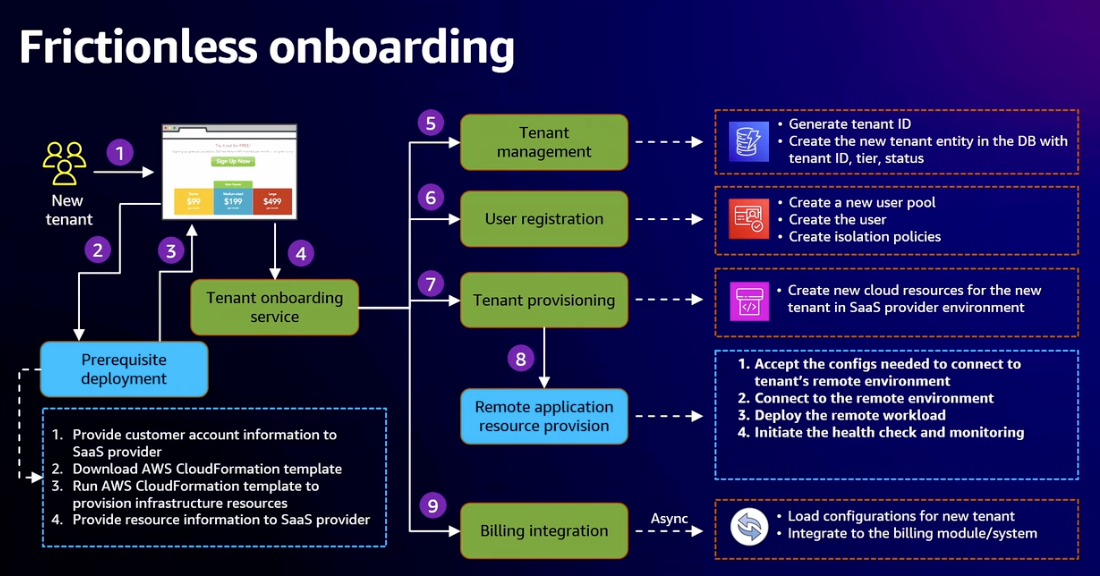
- Remote Management and Updates
- Need connectivity to remove environments
- Ability to push updates to applications
- How little can you get any with having remotely? The more you need, the more complex and expensive it becomes to manage
- Different flavors of anywhere
- Customer have their own AWS account
- Hybrid cloud
- On-premises
- Focusing on customer AWS account flavor
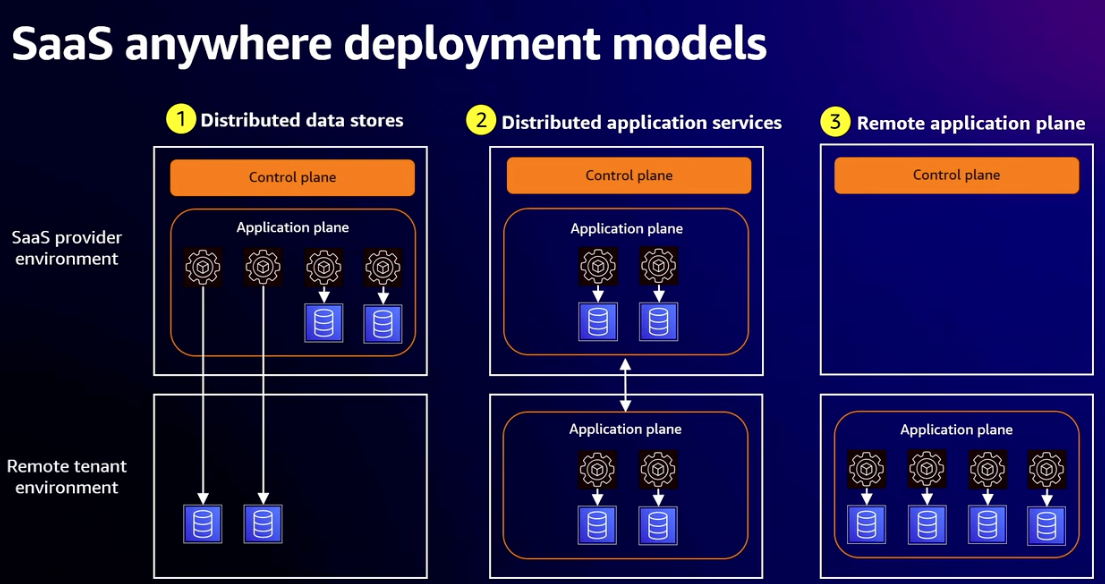
- Deployment models
- Distributed data stores (storage only)
- Distributed application services (storage and compute for some micro-services running remotely)
- Remote application plane (all your application data plane services running remotely, SaaS provider only manages control plane)
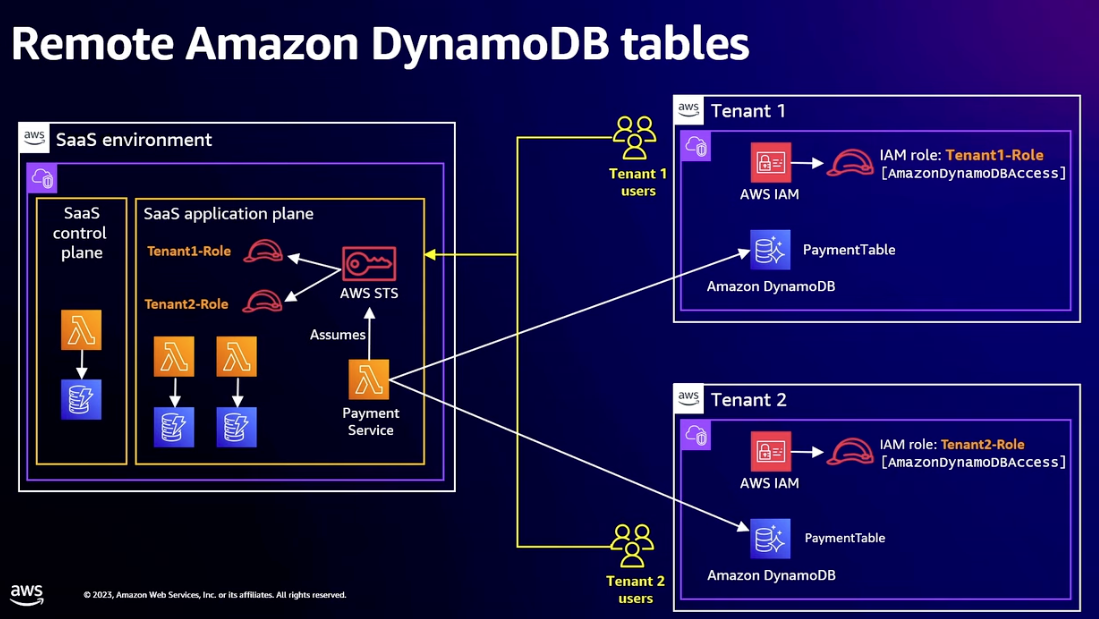
- Distributed data store
- Tenant maintains ownership and control of data
- Tenants could have too much existing data to transfer to Saas environment
- Tenant responsible for backup
- Use IAM roles to enable cross-account access
- Tenant has to create role and give SaaS provider permission to use the role
- SaaS application needs to assume each tenant’s role whenever it accesses that tenant’s database
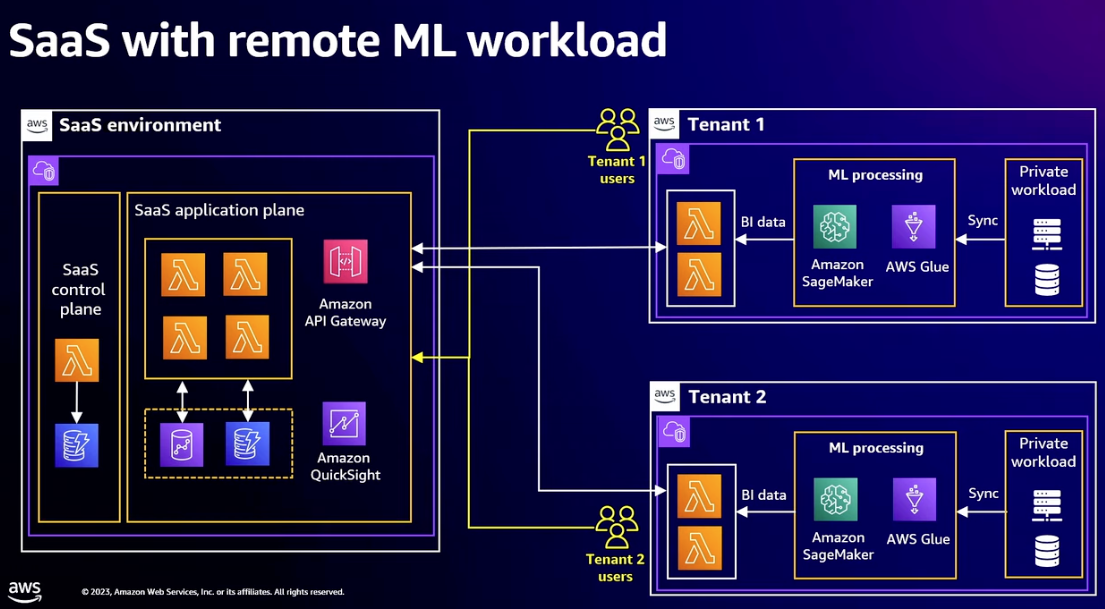
- Distributed application services
- Complete micro-service in remote environment
- SaaS provider should try and minimize number of remote services
- Tenant responsible for securing environment where application services run
- Consider using AWS PrivateLink to connect the two VPCs
- Remote application plane
- Tenant wants complete control
- Maybe needs to integrate tightly with other local services
- Remote deployments
- Whichever model, you need a system for remote deployments
- Need role in remote tenant that has permissions needed to grab and deploy latest build
- Control plane needs to automate pushing updates to all remote environments
- Cross-account observability
- Need infrastructure that sends selected observability metrics back from remote environments
5 things you should know about resilience at scale
Very similar content and style to the Beyond five 9s talk that happens every year. Worth a watch if you haven’t come across these concepts before.
- Dependencies and modes
- Dependencies introduce failure potential
- A model behavior is one in which a change to the system causes a total shift in how it operates
- Example: Normally using a cache, but falling back to the database
- Cache falling over shifts huge load onto the database which can’t scale fast enough to handle it
- DNS war story. Originally DNS servers queried database for changes. As service grew switched to database regularly publishing changes to S3 and servers reading objects from S3. Much more scalable. Unfortunately they left a fallback path in place if updates to S3 not having. System scales some more. At one point database starts lagging slightly behind when publishing, hits fallback threshold and all DNS servers instantly overwhelm it.
- Avoid modal shifts at scale. No fallback paths, no hard limits, no cliffs. If you need a shift in behavior, exercise it often.
- Design system so that it does less work rather than more if it all goes wrong.
- Preparing to fail
- Don’t try and design system that will never fail - not practically possible
- Assume system will fail and think about how to mitigate
- Blast radius, cellular architecture
- Don’t push all updates at once, partial deployment, canaries, rolling out to other regions, etc.
- Be careful with rollback threshold. The more instances you have, the more sensitive your threshold needs to be to pick up canary failure
- Why don’t you look specifically at canary availability when doing a canary deploy rather than overall availability?
- Reduce blast radius in time. Deploy and then immediately rollback. Then check if there would have been alarms afterwards.
- Queues
- Textbook use: Decoupling producer and consumer
- Great for small scale, intermittent outages in consumer
- If there’s a long outage, queue keeps growing
- Metric of queue health: number of items or better maximum age of items
- What do you do about backlogs?
- AWS builders library on unbounded queues
- Sidelining: On recovery Sideline old requests and use separate higher priority queue for new requests. Assumption is that older items are less relevant and producer may have given up and retried.
- Backpressure: Limit size of queue and if full propagate error state back to producer
- Know where your queues are, have a metric for how far behind consumer is, understand what your catch up rate is, have a queue bounding strategy
- Errors
- 4XX client errors, 5XX server errors
- When operating at scale will get 5XX rate close to but never at zero
- When writing a service make sure you separate 4XX and 5XX errors in your monitoring. 5XX is signal on health of your service, 4XX is mostly noise.
- 5XX: Generally unexpected, needs your attention, clients should retry
- 4XX: Expected all the time, may or may not be a signal, clients should not retry
- Looking at overall metrics can mask real problems. If you have sharded or cellular architecture need to look at metric for each shard/cell.
- Different customers will have different experiences.
- Interesting to look at 4XX by customer/tenant. Tells you something about how they’re using or abusing your service.
- Retries
- SDK clients have good built-in retry behavior
- Backoff, jitter, limited retries
- Retries mean when your service is having problems it will receive higher load
- Series of services 1 -> 2 -> 3 -> 4. If service 4 has outage and all services do repeated retries before failing back, then get geometric build up of retries hitting 4.
- Throttling: Service 4 could start throttling, 429 type errors should be propagated straight back without retries
- Contextual behavior: If service 2 and 3 known they’re internal, could propagate errors straight back and let service 1 control retry behavior
- Duplicate requests: Special case, where result is important, make two duplicate requests in parallel, use first response, ignore second. Propagate failure back if both fail. Avoids modal behavior where load increases if there’s an outage.
Solving large-scale data access challenges with Amazon S3
Based on the title I thought this would be about scaling to large workloads on S3. It’s actually about how you manage permissions and grant access, focusing on a new “Access Grants” feature.
- Bucket is secure by default, only owner has access
- Owner adds permissions for others
- By default new buckets now have public access and ACLs disabled - security best practice to do the same for your existing buckets
- IAM Basics
- IAM techniques using S3 prefixes
- IAM S3 bucket policies granting access to S3 objects with a particular prefix
- Usually need both a read and a list policy
- Each policy typically uses about 300 characters with a maximum of 20KB per bucket
- Which gives limit of about 30 different prefixes before you run out of policy space
- Alternative is to use IAM roles and define a role for each combination of permissions
- Soft limit is 1000 roles per account (5000 max)
- More complex to do for cross-account cases as will need bucket policy that grants access to the roles
- S3 Access Points
- What if you want to control access to huge number of different prefixes?
- Can setup S3 Access Points. An access point is an alias for a bucket with its own access policy
- Can have a separate access point for each prefix or group of prefixes
- Two level permission scheme. Put detailed permissions in access point policy and general permissions that apply to everyone in bucket policy.
- Soft limit is 10000 access points per account per region
- AWS Lake Formation
- What if you want to control fine grained access to structured data? e.g. Should only have access to particular column in parquet file
- Lake Formation uses AWS Athena to query structured data and lets you specify granular permissions for which columns particular roles have access to
- IAM session broker pattern for more scale/granularity
- What if you have lots of users, constantly changing teams? Or need very granular access control?
- Build your own session broker service.
- Authenticate caller
- Make access decision
- If yes call AWS STS AssumeRole API to create a session token that grants access to requested location
- Return STS token to caller who will use to sign requests to S3
- Works well because
- STS is high-volume, region specific data plane, highly available
- Minimal overhead for S3 to validate token, can achieve high scale and throughput
- Minimal number of static IAM resources
- Session broker service scales with number of sessions, not data or object requests
- S3 Access Grants
- Managed service instead of building your own session broker
- Three main use cases
- Pain of managing monolithic bucket policy
- Mapping users to data without having to implement the same thing in each app
- Auditing users - want to know who accessed data, not just app that implemented access controls
- Access grant is tuple combining S3 prefix, access level (read or write) and identity
- Identity is either IAM id or a “directory identity”
- Built as layer on top of IAM - not a bypass
- Works in same way as a DIY session broker service
- Addresses use cases
- Can use lots of discrete access grants rather than one big bucket policy
- Mapping of users for multiple apps can be done in one place, in S3 Access Grants
- Integrated with IAM identify center. CloudTrail event now includes an onBehalfOf object which specifies user directly
- App Integration
- Call S3 Access Grants to get session token, just like with session broker case
- Simple case: caller’s IAM identity matches IAM identity in access grant
- Response includes STS credentials + which access pattern you matched (can reuse for other objects if still match)
- New case: Application authenticated end users
- Makes use of IAM identity center service (previously called Single Sign On)
- Uses SCIM protocol to sync identities from external providers like Okta into identity center
- Identity center also has its own users/groups system if you don’t have an external provider
- New: Trusted Identity Propagation. Allows identity center ids to be used in services like S3
- App does it’s usual single sign on thing to authenticate user with whatever provider you use
- App makes request to identity center to get equivalent identify center id
- Blog post with all the details Developing a User-Facing Application Using Identity Center and S3 Access Grants
- Finally app makes request to S3 access grants with it’s own IAM role and the identity center id as extra context. Gets back STS credentials that represent IAM session for this app operating on behalf of this user.
- Access Grants is a regional feature. Grants are for buckets in same region and same account.
- Cross-account access supported (assuming the appropriate cross-account access policies are in place)
- Creating grants
- UI in the console
- Grant has account id, grantee (list of identities), permission, S3 prefix, location
- Location is advanced feature, usually default. Combine location and prefix to get actual object name.
- Location is associated with an IAM role that is used in the resulting credentials if the grant matches
- Can define multiple locations with different roles if you need that flexibility
- Works transparently with S3 objects encrypted with KMS
- EMR has integration with access grants
“Rustifying” serverless: Boost AWS Lambda performance with Rust
Step by step guide to writing Lambdas in Rust. Three strategies: Using Rust bindings to allow existing Python code to call Rust, writing a standalone Rust lambda, writing a Lambda extension that can be included as a layer by a Lambda using any runtime.
- Scenario: Company building serverless app on Lambda/Python. Running into performance and cost challenges.
- Decided to switch runtime to Rust
- Incremental approach, can’t immediately throw everything away and rewrite in Rust
- Rust bindings
- Replace most performance sensitive part of code using Rust
- Expose Rust functionality in python using Rust bindings
- PyO3/maturin tool will generate bindings for Rust code and package them up as python “wheels”
- Official Rust SDK aws-sdk-rust. Currently in developer preview. Built in support for async.
- Make sure you use –strip, –release and –zig flags when building production release during maturin
- On python side just import the module, create instance of class in Lambda initialization and call it in request handler
- Include .pyi interface definition file in package to enable intellisense for consuming developer
- Used SAR-measure-cold-start and aws-lambda-power-tuning to measure performance and cost
- Get same performance using a quarter of the memory (hence 4X cheaper)
- Comparing same size Lambda, get 4X lower cost per invocation
- Cold start performance is 3X faster. Important for front facing Lambda, irrelevant for batch.
- Large part of that is due to size/inefficiency of python boto3 package. Can get most of the benefits by replacing those parts with Rust+binding
- Rewrite Lambda in Rust
- For simple Lambda you might as well rewrite the whole thing
- AWS SAM has built in support (beta) for Rust using cargo-lambda package
- Lambda deployments require a language specific runtime layer between the Lambda native runtime and your code
- For languages, like Rust, which compile to native code, you need to include the runtime in your build
- For Rust, AWS has aws-lambda-rust-runtime. This is officially an “experimental” package, subject to change.
- AWS provides the aws_lambda_events crate that defines all the lambda related type definitions you’ll need
- Currently have choice of Amazon Linux 2 or Amazon 2023 Lambda native runtime which you’ll also bundle in to final build
- Performance is even better, particularly with low memory. For simple Lambda, performance is same at all sizes, including 128 MB. At that size you’re 5X faster than Python, which only gets comparable (but slower) performance at 512MB or higher.
- Cost is 4X lower, as before
- Biggest change is cold start. Now 6 or 7 times faster once you ditch Python runtime startup.
- Lambda Extensions
- Lambda extension is a separate process that runs in same execution environment and communicates with your handler.
- Extension has own lifecycle. Standalone handler stops running as soon as it returns a response. If you add an extension, the extension can keep running even after the handler has exited. Can return response to caller and do clean up or other fire and forget work in extension. Good use case is writing out analytics data.
- As extension is separate process, can use different language from handler
- As Rust is native, aren’t adding another big virtual machine. Small and fast.
- aws-lambda-rust-runtime/lambda-extension is special case runtime for extensions
- Extension gets added as a layer to Lambda runtime
- Using extension reduces latency because you can return sooner. Downside is small increase in cold start times as more to initialize.
- Learning Rust
- The official Rust book, The Rust Programming Language is great.
- Use rustlings for small exercises and tests as you read through
Surviving overloads: How Amazon Prime Day avoids congestion collapse
Great explanation of congestion collapse with lots of examples. Some takeaways I haven’t seen before. In particular, limiting number of retries. Forget about exponential backoff, never do more than one retry! Beyond that, make sure that in aggregate, your retry rate is much less than one.
- Delicate balance between reducing compute cost and increasing chance of a brown out
- What is congestion collapse?
- System gets slightly overloaded and then goes into death spiral
- Resource utilization (CPU? Disk? Network?) goes to 100%
- Queues get longer and longer
- Eventually system is doing zero productive work
- System gets stuck in this state, very difficult to unstick even as external load comes down
- Examples
- Metering lights to control rate of cars joining highway
- What happens if highway gets too congested? All the cars stop
- Congestion stops traffic flowing
- Takes a long time to clear
- Metering lights go red if highway density getting too high, trying to avoid congestion collapse
- Mother’s day phone problem
- Everyone calls their Mom on Mother’s day
- Eventually no lines available and get a busy signal
- Caller tries again, and again
- Network is saturated waiting for dial tones
- Eventually phone companies replaced busy signal with a recorded message: “All lines are busy now, please try your call later”
- TCP Congestion
- Each sender transmits at some speed
- Routers direct many inputs to an output
- Egress bandwidth may be less than total ingress, so router queues
- Queues build, routers have finite memory, eventually packets are discarded
- Discarded (NACK’d) packets are sign of congestion overload
- Can’t just retransmit lost packets, putting more load on system would cause congestion collapse
- Doomed packets waste bandwidth
- Hard problem. Eventually came up with a protocol that shrinks “send-window” when congestion detected, reducing load in such a way that you achieve exponential backoff of the overall transmission rate.
- Web application overload
- Assume application can handle 100 TPS, what happens when demand is 110 TPS?
- Queue builds up, user experiences delay, users hits reload, effective rate now 220 TPS
- Death spiral starts, user keeps reloading, 330, 440 TPS
- Whatever responses do come back are ignored because user had already given up and reloaded again
- Try throttling the server by discarding half of incoming packets. Back down to 220 TPS and queue still growing.
- Stateful death, application is stuck
- Simple recovery strategy: flush all the queues so you start processing new requests and can make progress for users still waiting for a response
- Service oriented architectures make it worse, if each service retries get doubling behavior
- Same problem discussed in resilience at scale talk above
- Prime Day 2018 outage
- Distributed hash table behind 100s of routing servers
- Hot key for specific item overloaded hot partition
- Systems in layers above started retrying. Fives times retry at multiple levels compounding up.
- Hidden queue: Database instance had a 1MB TCP receive buffer - enough for a 1000 requests
- 3 hours of scrambling, multiple fixes pushed out to get it under control. On prime day.
- Followed up with thorough reviews and testing for congestion related failures
- Changed retry policy: never more than 1 per request
- Aim was to get to asymptotically no retries - each client instance tracks number of successful requests. Not allowed to retry until you’ve had 100 successful requests. Retry rate of 1%.
- Restricted size of large/unbounded queues
- Crush testing - drive traffic to component over limit it’s designed for and see what happens to latency. If it grows there’s a hidden queue.
- Availability vs Efficiency
- Traditionally add excess capacity to avoid overload and collapse. Don’t get too close to max loading.
- BUT efficiency requires minimizing capacity - trying to be close to max loading
- Random traffic variations happen -> overloads happen
- Need better ways to handle random overloads, avoid congestion collapse, degrade gracefully
- Be willing to fail requests, avoid retries to stressed services
- Metering lights to control rate of cars joining highway
- Evading congestion collapse
- Overloads will happen
- You have to indicate overload state back to caller so they can avoid retries
- Accept that overloads require service degradation, be willing to throttle and fail requests
- Be very careful about retries, especially for timeouts. Bound retries at less than 1.
- If you retry, share/gossip across callers
- Per-request exponential backoff with multiple retries DOES NOT WORK. Need to restrain growth of aggregate retries
- Try to get more efficient during overload
- Consider adaptive batching to amortize setup costs across requests
- Read more things from the queue the fuller it gets
- Crush test beyond maximum load
- Testing at expected load is not enough
- Test to failure and beyond
- Watch for unbounded latency
- Fail fast is good
- Watch for problematic retry storms
- After overload, reduce test call rate to normal and see how quickly latency recovers
- Less than a minute is good, more suggests a problem queue
- How do you apply this to your apps on AWS?
- Detection
- CloudWatch for CPUUtilization, DiskReadOps, DiskWriteOps, NetworkIn, NetworkOut, NetworkPacketsIn, NetworkPacketsOut
- High resolution metrics if you have Elastic Network Adaptor (ENA) enabled, e.g. pps_allowance_exceeded
- ALB new anomaly detection feature for excessive 5XX errors
- Create dashboards
- Avoiding overload
- Keep malicious traffic out - stick your app behind CloudFront and enable AWS Shield Advanced / WAF
- Ask users to back off - AWS WAF can be configured to return 429 or error page after rate-limit reached
- Throttle upstream
- Use decoupled systems (e.g. SQS queue rather than direct call) where services might have different scaling behaviors
- Producer can look at ApproximateAgeOfOldestMessage metric to see whether consumer is getting overloaded and slow down
- Consumer could drop messages that are too old
- Crush testing
- Model application on smaller scale
- Test with all dependencies
- Test each layer separately
- Can replay real user traffic, e.g. using Amazon VPC traffic mirroring
- If you have too little data can end up being entirely cached
- Alternative is to simulate traffic with a tool like iPerf (open source)
- Chaos engineering
- Introduce faults/pauses using Fault Injection Simulator
- See how quickly you can recover
- Verify that runbooks are fit for purpose during incidents
- Detection