You’re building a full stack application that enables teams of people to do … something. In order to manage the process of doing something, the teams collaborate by creating, filling in, finding, sorting and archiving forms. There will be some industry specific bits of workflow that let you convince yourself that you’re not building the same thing over and over again.
There are probably lots of different types of forms relevant to the different phases of doing something. Each form has a distinct set of fields. If you’re doing anything even vaguely enterprisey, the set of fields will be customizable.
There are so many forms that they need to be organized into collections of related forms. You might have a set of forms related to a particular project, or a particular person or thing. Maybe you have so many collections that you need collections of collections too. If you’re building a multi-tenant application you have another level of hierarchy on top.
The heart of your application is a GUI that lets you navigate to a particular collection of forms displayed in a grid view. From here you can sort and filter, display a selected form in an editor, or fill out a new form.
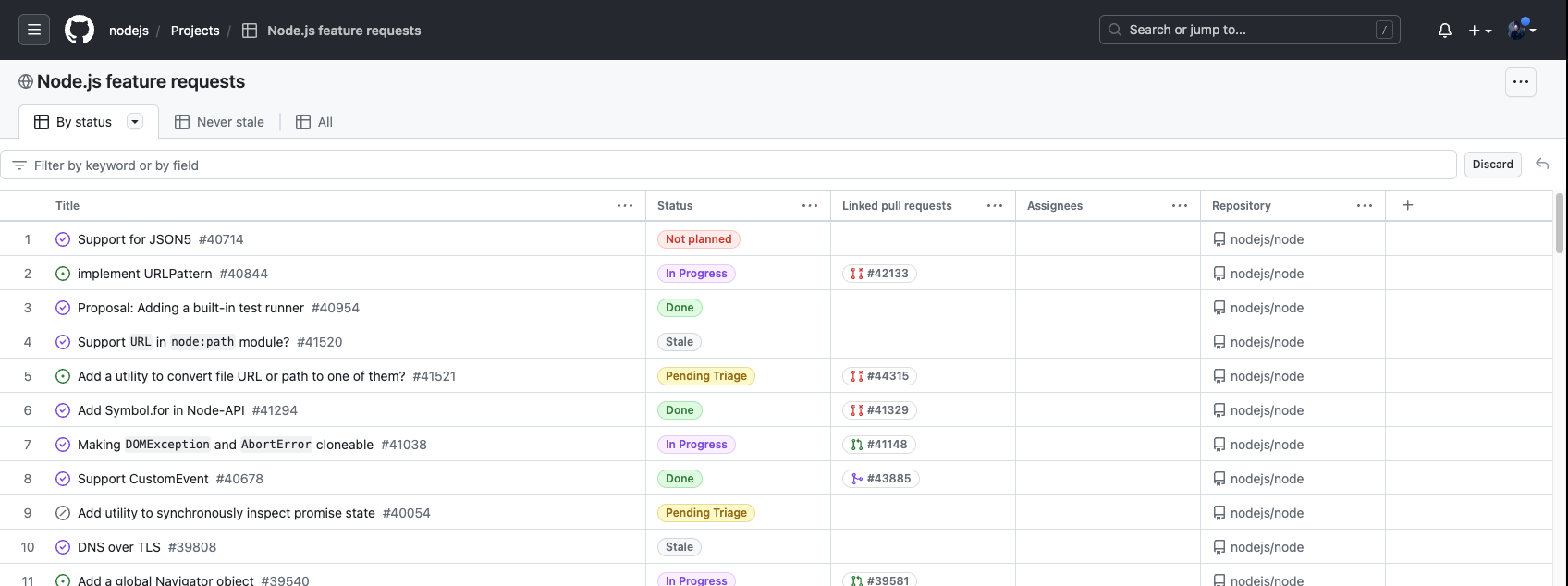
Oh look, here’s an example. This is a project in GitHub (the NodeJS feature requests project). It’s a collection of issues. You have a Grid View that shows you the issues in the project. Fields in the issue can be displayed as columns in the grid view. You can add additional custom fields if you want. You can sort the grid by any column, or group by any column, or both at once. You can filter one or more columns too. Projects are owned by Organizations, which are GitHub’s tenants.
This is a cloud application, so there’s a database in the backend somewhere, with some app servers sitting between the client and the database. The grid is a view on the data in the database.
The question that concerns us is, how do you best implement something like this? What are the access patterns in the client? What sort of API do the app servers need to provide? Most importantly of all, how do you store and query the data so that your application is responsive and scalable?
Limits
Hold on, before you rush off to start solutioning, you need more context. When a PM comes to you, describing the application they want you to build, what should your first question be?
What are the limits?
If the PM is non-technical, you’ll now do the dance where they tell you that there aren’t any limits and you’ll explain that there are always limits and that it’s better to know what they are.
If you don’t define your limits …
- you don’t know if the system is capable of meeting them
- you can’t formulate an effective test plan
- the system will be over engineered and take too long to build
- you won’t know how much the system will cost to operate
- your customers will find where the system breaks
Let’s go back to our example. What are the limits for GitHub projects ?
- No more than 1200 issues displayed in the grid view
- No more than 10000 archive issues (issues not in active use can be archived so they no longer appear in the grid view)
- Issues can have at most 50 fields
- Fields can store text, numbers, dates, enums and relationships to other issues
- Text fields can contain at most 1024 characters
- Enum fields can have at most 50 values to choose from
The Easy Way Out
GitHub projects has some pretty sane limits. In the worst case an issue requires 50KB (50 text fields of 1024 characters), and an entire project 59MB (1200 issues of 50KB).
Text is displayed and edited using a single line entry box, so in practice you’re unlikely to get anywhere close to the worst case size.
With limits like these, you have the option of implementing everything client side. When the user opens a project, download everything that can appear in the grid. If necessary, all 1200 rows and 50 columns. If we assume a minimum of ADSL broadband at 10Mbps, then the absolute worst case is 60 seconds to open the project. If you look at a more realistic configuration with 10 fields and 100 bytes per field it will take about a second for 1200 issues.
The data fits very comfortably in memory on even the most constrained client. You can load it all into your grid control and let the user scroll through it. Your users can sort and filter to their heart’s content with instant response times.
On the database side, you can represent the data pretty much however you want. You need to be able to create, update and query individual issues. The one requirement is that you have an index on project id so that you can efficiently query for all the issues on a project.
How is this actually implemented in GitHub?
GitHub uses server side rendering. When you open the URL for the project, the html document returned includes the complete set of issues inline. Everything else happens client side.
The Hard Way
Unfortunately for me, the systems I’ve worked on had limits that were considerably less sane. The PMs grudgingly agreed to a limit of 100,000 items in a project. Although they reserved the right to increase that limit if customers demanded it. We had text, number, date and enum custom fields too. With a limit of 100 fields of each type.
Over the years I’ve worked with multiple teams that have implemented variations of this feature. The forms and collections of forms have different names. The bits of workflow that connect everything together are specific to each feature. However, the core of each feature is always the same. A grid view over a collection of forms.
The teams differed in their preferred language stacks, their level of maturity, and their experience with databases. I’ve seen a variety of patterns and anti-patterns come and go. Now I’m going to share what I’ve learnt with you.
Next time, we’ll kick things off with the classic Normalized Relational Database pattern.