I’m using TSDoc comments to provide IntelliSense based documentation for my open source project. Now I want to do more. Enter API Extractor.
API Extractor
API Extractor is a Microsoft open source tool. It reads the .d.ts type files output by the TypeScript compiler (which include any relevant TSDoc comments copied over from your source code) and does three things with them.
- Generates an API report. Each run acts like a linter focused on your exported API and documentation. Comparing each run against the previous reveals any breaking changes in your API.
- Generates a rollup
index.d.tsfile containing just the definitions that are part of your public API. - Generates an “API model” that can be used to create nicely formatted API reference documentation.
I already have a solution for rollup generation but it’s nice to know I have an alternative if needed. The rest of it looks like just what I need.
Installation
Let’s take if for a spin.
npm install -D @microsoft/api-extractor
added 30 packages, removed 6 packages, and audited 1015 packages in 5s
It’s pretty chunky and takes me over a thousand dependencies in one jump. The documentation recommends that you start with a template config file that it will create for you.
% npx api-extractor init
api-extractor 7.47.0 - https://api-extractor.com/
Writing file: /Users/tim/GitHub/infinisheet/api-extractor.json
The recommended location for this file is in the project's "config" subfolder,
or else in the top-level folder with package.json.
Config File
The config file produced includes full reference documentation for each option as comments. It’s huge. Pages and pages of it. It’s also a sea of red squiggly lines in VS Code because JSON files don’t support comments.
Except there are lots of JSON files with comments that VS Code doesn’t complain about. For example, tsconfig.json.
Rabbit hole time. Internally, VS Code supports two parsers for JSON. A standards compliant one for the “json” format, and another one for “jsonc” which does support comments. You can setup file associations that map file patterns to the parser to use. By default tsconfig.json and tsconfig.*.json are mapped to “jsonc”.
Which makes sense. TypeScript is a Microsoft product. Apparently, some third party config file formats also have default rules that map them to “jsonc”. However, for some reason, “api-extractor.json” gets no special treatment and you have to setup a file association yourself.
I edited the generated config file to set the mandatory mainEntryPointFilePath property to point at the dist/index.d.ts file generated by my Rollup build. You would normally point API Extractor at the set of .d.ts files output by the TypeScript compiler. However, that all happens inside my Rollup pipeline. I don’t want to mess with that if I don’t have to. In theory, everything API extractor needs is in the built output which should be quicker to read too.
I also disabled API Extractor from trying to generate its own rollup of my rollup.
First Run
Let’s see what happens when I run it.
% npx api-extractor run --local --verbose
api-extractor 7.47.0 - https://api-extractor.com/
Using configuration from ./api-extractor.json
Analysis will use the bundled TypeScript version 5.4.2
*** The target project appears to use TypeScript 5.5.2 which is newer than the bundled compiler engine; consider upgrading API Extractor.
Writing: /Users/tim/GitHub/infinisheet/packages/react-virtual-scroll/temp/react-virtual-scroll.api.json
Generating complete API report: /Users/tim/GitHub/infinisheet/packages/react-virtual-scroll/etc/react-virtual-scroll.api.md
Error: Unable to create the API report file. Please make sure the target folder exists:
/Users/tim/GitHub/infinisheet/packages/react-virtual-scroll/etc
Warning: dist/index.d.ts:55:1 - (ae-missing-release-tag) "VirtualInnerProps" is part of the package's API, but it is missing a release tag (@alpha, @beta, @public, or @internal)
Warning: dist/index.d.ts:55:1 - (ae-unresolved-link) The @link reference could not be resolved: The package "@candidstartup/react-virtual-scroll" does not have an export "VirtualInnerComponent"
...
Error Analysis
I don’t like the look of that message about TypeScript versions. I’ve just installed the latest version of API Extractor. Digging deeper suggests that this is a common state of affairs and generally nothing to worry about. API Extractor only uses the TypeScript compiler to read the *.d.ts file which is much simpler than the full source code and less likely to have significant changes between Typescript versions.
I changed the config so that the API report goes into the project folder rather than trying to write it to a non-existent ./etc folder.
That just leaves the long list of errors. Despite being described as warnings, the documentation says they result in a nonzero exit code which would cause production builds to fail. You can configure things so that selected warnings go into the API report instead. Looking at the generated react-virtual-scroll.api.md, there are already warnings being sent there.
// Warning: (ae-forgotten-export) The symbol "FixedSizeItemOffsetMapping" needs to be exported by the entry point index.d.ts
//
// @public (undocumented)
export function useFixedSizeItemOffsetMapping(itemSize: number): FixedSizeItemOffsetMapping;
Refactoring Exports
I’ve been subconsciously following a policy of explicitly exporting the top level symbols that a user would directly import but not dependent symbols. Up to this point everything has worked. API Extractor is suggesting that every dependency needs to be explicitly exported.
After some research, I think API Extractor is right. What I’m currently doing works for simple cases. IntelliSense help isn’t limited by exports. You can use the value of a property of unexported type. There are circumstances where the compiler can infer types.
It won’t work if the user writes code that accesses unexported types explicitly. For example, extending a type. Or declaring a variable of that type.
The correct thing is to export every type that is part of the public surface area of the API. So, I went back through and made sure everything referenced by the public API is explicitly exported. To make life simpler, I divided the source components within my module into “public” components and “internal” components. I export every type in a public component. Most internal components have no types publicly exported. There are a couple of special cases where public components use a type from an internal component. In those cases I explicitly export just that type.
I needed a little bit of refactoring to keep things maintainable. The VirtualBase.ts component contains functionality shared by VirtualList.tsx and VirtualGrid.tsx. Most of it is public apart from one bit of common implementation. I moved that into a new internal VirtualCommon.ts component.
That leaves me with this set of module exports.
export * from './VirtualBase'
export * from './VirtualGrid'
export * from './VirtualList'
export * from './useFixedSizeItemOffsetMapping'
export * from './useVariableSizeItemOffsetMapping'
export type { ScrollState, ScrollDirection } from './useVirtualScroll';
Release Tags
API Extractor expects you to use a formal system of API management. Every item in the API should be tagged with one of four release tags. These are @public, @beta, @alpha and @internal. The .d.ts rollup feature can trim items from the rollup based on the release tag. For example, you can generate a public.d.ts that contains only @public items, and a beta.d.ts the contains both @public and @beta items.
For now, I don’t want to bother with explicitly adding release tags to everything in the API. I’ve disabled the warning.
"messages": {
"extractorMessageReporting": {
"ae-missing-release-tag": {
"logLevel": "none"
}
}
}
Unresolved Links
That left me with two remaining errors
Warning: dist/index.d.ts:50:5 - (ae-unresolved-link) The @link reference could not be resolved: No member was found with name "maxCssSize"
Warning: dist/index.d.ts:185:5 - (ae-unresolved-link) The @link reference could not be resolved: No member was found with name "data"
Both of these are real problems caused by typos in my TSDoc comments. I fixed the broken links and moved on.
Package Documentation
That fixed all the warnings in the console and API report. I was left with one intriguing comment at the bottom of the report: // (No @packageDocumentation comment for this package)
Comments with the @packageDocumentation tag are used by the API documentation generator to describe the package as a whole. As well as being tagged, it needs to be the first comment in the entry point index.d.ts.
Easy, I thought. I can add one at the top of index.ts. It’ll get copied into index.d.ts by the TypeScript compiler. Unfortunately, Rollup helpfully removes the comment when generating my rolled up index.d.ts because it doesn’t apply to anything.
I tried the hack of defining a dummy exported type and applying the comment to that. It does make it into the rolled up file but API Extractor still complains because it needs to be literally the first thing in the file. Rollup doesn’t preserve order.
To make it work I’d need to rework my build pipeline so that API Extractor runs on the output of the TypeScript compiler before Rollup generates the final bundle. Or I could use API Extractor to produce the rolled up index.d.ts.
Before I do any of that I need to check what the generated documentation is like. There’s no point changing my build process if the output is rubbish.
API Documenter
API Extractor relies on a companion tool, API Documenter, to generate documentation. API Extractor outputs a “document model” JSON file for each package. API Documenter reads the document model and outputs a Markdown representation of the documentation. For monorepos, API Documenter can read multiple document models and generate combined documentation including cross-package links.
You then take the generated Markdown files and do whatever you want with them. You could upload them to GitHub and use the GitHub integrated Markdown viewer, publish them through GitHub Pages, or push them through a custom static website publishing pipeline.
Installation and First Run
% npm install -D @microsoft/api-documenter
added 4 packages, and audited 1019 packages in 3s
I also need to update the API extractor config file to output a document model .api.json file. By default it gets put into a temp sub-directory. Annoyingly, API Documenter has a different default location for reading document models. I can override that on the command line. By default, output is written to a markdown sub-directory.
npx api-documenter markdown -i temp
api-documenter 7.25.4 - https://api-extractor.com/
Reading react-virtual-scroll.api.json
Deleting old output from ./markdown
Writing @candidstartup/react-virtual-scroll package
Marking Down Markdown
I need to publish the Markdown somehow to see if the output is any good. I have a quick and dirty way that I’ve used before. I copy the markdown directory into my local repo for this blog and let my local Jekyll publishing environment handle the rest.
It didn’t come out as I expected.
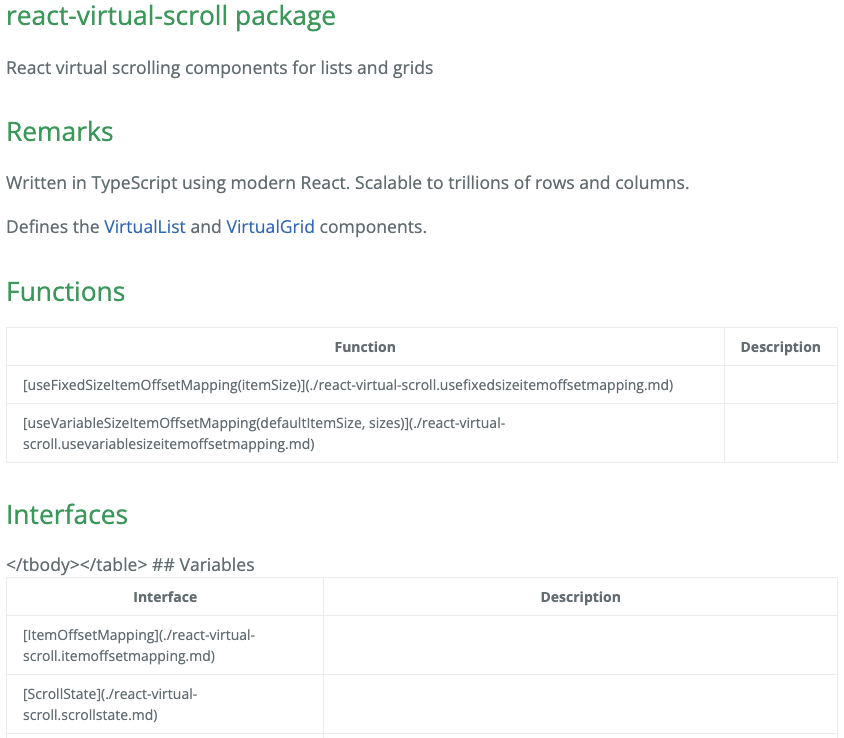
The publishing pipeline is meant to convert relative Markdown links like [ScrollState](./scrollstate.md) to html, renaming .md to .html in the process. Most of the links are left as Markdown. Those that are converted to html still have the .md extension and take you to the Markdown source. Then there’s lots of random garbled markup visible in the output.
I initially thought the problem must be with my local Jekyll setup. I changed a few likely looking configuration options. Updated to the latest version. Still broken.
To rule out my local environment I temporarily checked the Markdown files into GitHub. They look fine in GitHub’s Markdown viewer. Links are converted and functional. No visible garbled markup.
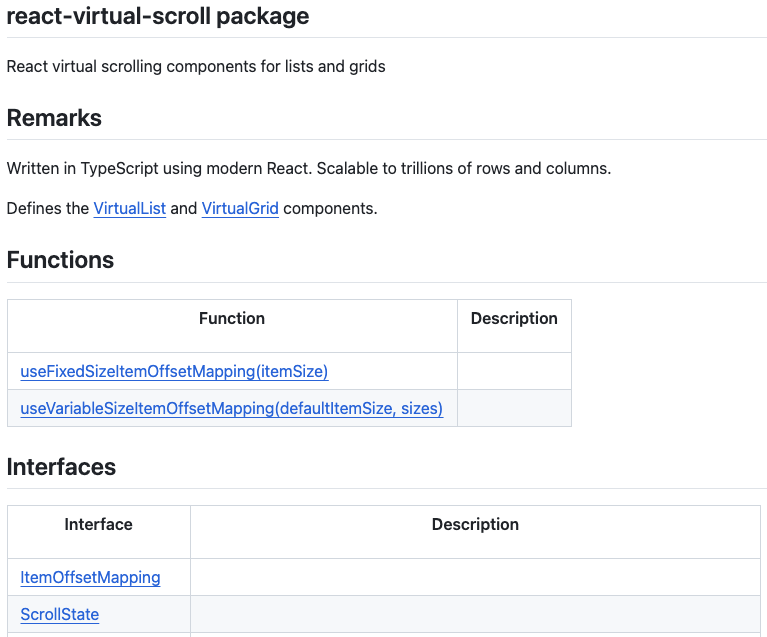
However, once they’re published to the blog via GitHub Pages I get the same garbled mess that I see locally.
My next thought was that there must be something wrong with my hacked together Candid Startup Jekyll theme. I uploaded the Markdown again to a separate repo and setup GitHub Pages publishing using the defaults.
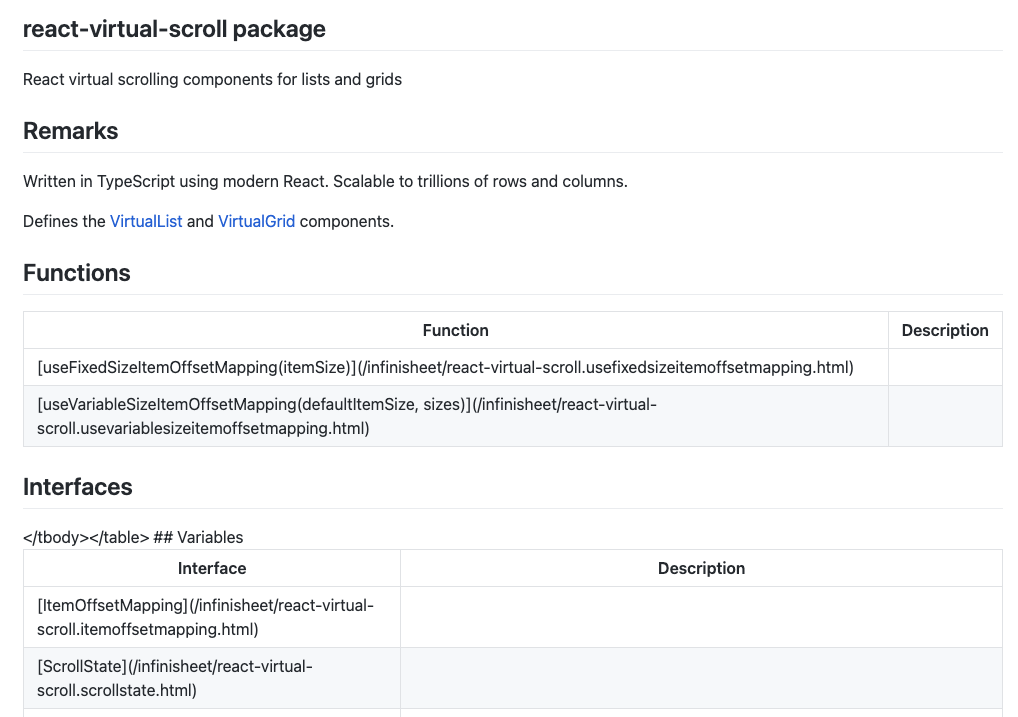
This time the extensions have all been converted from .md to .html. However, most of the links are left in Markdown format and the garbled markup is still there.
Finally, I started to wonder about the quality of the API Documenter output. The Markdown output includes html tables with Markdown content in each cell.
<tbody><tr><td>
[ScrollState](./react-virtual-scroll.scrollstate.md)
</td><td>
Does that really work? No it doesn’t. It turns out that this was introduced in API Documenter v7.24 a couple of months ago. Prior to that the output used Markdown tables. This has broken lots of Markdown publishers and the change is likely to be rolled back.
I downgraded to v7.23.38 and regenerated the Markdown. As expected all the tables now use Markdown syntax throughout. I ran the output through my local Jekyll publishing and all the links are converted to html. Suffixes are still .md however.
Back to checking my Jekyll setup. Facepalm moment. I’d forgotten that I tried using relative links between blog posts when I was setting things up. Relative links are only supported for normal pages. I’d left things with relative links disabled. Once I removed the leftovers from my original experiments the links worked correctly.
Unfortunately, there’s still some broken formatting. Comments with multiple paragraphs result in Markdown with explicit html paragraph tags.
| [VirtualList](./react-virtual-scroll.virtuallist.md) | <p>Virtual Scrolling List</p><p>Accepts props defined by [VirtualListProps](./react-virtual-scroll.virtuallistprops.md)<!-- -->. Refs are forwarded to [VirtualListProxy](./react-virtual-scroll.virtuallistproxy.md)<!-- -->. You must pass a single instance of [VirtualListItem](./react-virtual-scroll.virtuallistitem.md) as a child.</p> |
Put that in a Markdown table and GitHub Pages can’t handle it.

Giving Up
At this point I gave up. Generating Markdown as an intermediate format is a nice idea but it doesn’t work. The pure Markdown format is too limited for the documentation that API Documenter wants to generate, so they have to resort to using html tags. It’s then a complete lottery how downstream Markdown formatters deal with it. They’ve tried mixing Markdown and html in different ways, none of which work for me.
Tidying Up
I am getting some value from the API Report functionality, so I decided to leave API Extractor in place for that. I just need to tidy things up first.
API extractor uses the same config file system as the TypeScript compiler. You can put all the common config in one file and reference it in a stub config in each package. Like the TypeScript compiler, paths are relative to the config file they’re defined in. However, API Extractor has a nice trick to avoid duplication. You can define a projectFolder variable in the per-package stub.
{
"extends": "../api-extractor-base.json",
"projectFolder": "."
}
You can then use <projectFolder> as the base for paths defined in the common config. For example, the path to the main entry point for each package is <projectFolder>/dist/index.d.ts.
Build Workflow
The API report is designed to be checked into source control. During local development builds (passing the --local flag to API Extractor) the file is updated based on changes to the API. You can then review the changes and check them in, with the appropriate conventional commit message to describe the type of change.
During production builds the checked in API report is compared against a generated one. If they’re different, the build fails. Someone must have inadvertently checked in an API change.
I updated my NPM build scripts and Build CI GitHub actions workflow. I now have a devbuild target I can use locally to build, lint and update the API report. The Build CI workflow includes a production API report step.
Conclusion
API extractor does three things. One of them is useful, one doesn’t work and one I have another solution for. If I’d known in advance I might not have bothered with API Extractor. It’s a heavyweight solution for a glorified lint plugin.
I think I’ll need to look elsewhere for documentation generation. Luckily, there are other options out there. We’ll try one next time.