Last time, we defined a minimal data interface and hooked it up to VirtualSpreadsheet. Now I need to get a better understanding of the standard spreadsheet data model so that I can flesh out the interface to match.
I’m aiming for an initial data model that’s Excel compatible with the ability to extend to more data types in future.
Excel Data Model
The core Excel data model is surprisingly simple. Each cell value can be one of four types.
- Number (64 bit floating point)
- Text (Unicode String)
- Logical Value (TRUE or FALSE)
- Error Value
There are up to 12 different error types depending on Excel version and source.
#NULL!#DIV/0!#VALUE!#REF!#NAME?#NUM!#N/A#GETTING_DATA#SPILL!#UNKNOWN!#FIELD!#CALC!
Hold on, what about dates, time and currency?
They’re all stored as numbers but formatted differently for display. Each cell has an associated format string which defines how values are formatted.
Many different formatting patterns are supported. It’s a mini-language that has clearly grown over time, with many edge cases, particularly around dates.
By default, a General format is used. If the value is a number, a bunch of hard coded formatting rules are applied. Booleans are formatted as TRUE or FALSE. Strings are displayed as is. Otherwise, formatting proceeds using rules encoded in the format string.
The Excel UI lets you pick from a list of built-in formats or create a custom format. Internally everything uses the same format pattern language.
Cell Value
Instead of returning a string for each cell value, I now return a CellValue type.
export type CellErrorValue = '#NULL!' |
'#DIV/0!' |
'#VALUE!' |
'#REF!' |
'#NAME?' |
'#NUM!' |
'#N/A' |
'#GETTING_DATA' |
'#SPILL!' |
'#UNKNOWN!' |
'#FIELD!' |
'#CALC!';
export interface CellError {
type: 'CellError',
value: CellErrorValue;
};
export type CellValue = string | number | boolean | null | undefined | CellError;
The Number, Text and Logical Excel data types map directly to string, number and boolean types in TypeScript. The null and undefined types can both be used to represent empty cells. The difference is that null is used when a user has explicitly made a cell blank, while undefined represents a cell that has never had a value.
I talked last time about being able to combine multiple data stores into a single view. If a cell is undefined in the first store, you would try the next store and so on. If a cell is null in the first store, you would immediately accept that the cell is empty.
The only complex type is CellError. It’s represented as an object so that it can easily be distinguished from the other types. It has a value property which is one of the 12 possible error values. It also has a type property which is always the string “CellError”.
Discriminating Unions
CellError uses a common TypeScript pattern called a discriminating union. This is what lets us add support for additional types in future. Each additional type, for example CellImage or CellBigInteger, would be represented as an object with a different literal type string.
You can write runtime code that checks whether a CellValue is an object and then checks what type the object has. If your code is correct, TypeScript’s narrowing analysis infers the type of object being accessed without having to do anything else.
function asString(value: CellValue): string {
if (value === null || value === undefined)
return "";
if (typeof value === 'object')
return value.value;
return value.toString();
}
For example, with the current definition of CellValue, TypeScript can infer that any CellValue that’s an object must be a CellError and it’s safe to access the value property. If I later add additional object types to CellValue, TypeScript will report an error until I add code that checks the type property before accessing value.
Spreadsheet Data Interface v2
The new version of SpreadsheetData returns a CellValue from getCellValue. It also adds a getCellFormat method. This returns a formatting string if one has been defined for the cell, otherwise undefined.
export interface SpreadsheetData<Snapshot> {
subscribe: (onDataChange: () => void) => () => void,
getSnapshot(): Snapshot,
getRowCount(snapshot: Snapshot): number,
getColumnCount(snapshot: Snapshot): number,
getCellValue(snapshot: Snapshot, row: number, column: number): CellValue;
getCellFormat(snapshot: Snapshot, row: number, column: number): string | undefined;
}
Cell Formatting
Formatting is standard spreadsheet functionality that doesn’t care how big the spreadsheet is. I have no desire to write it myself. Fortunately, I found two open source implementations on NPM. Even better, neither of them add any additional third party dependencies.
SSF is a mature package that’s part of the SheetJS product. It has one of those dual licenses with a basic open source “community version”, and a more fully featured commercial version. It was last published to NPM four years ago. Newer versions are only available direct from SheetJS.com.
The alternative is numfmt. This is a fully open source, standalone package with an MIT license. It supports the same features as SSF plus localization (only available in the commercial version of SSF) and parsing of input values.
Obviously, I’m going to try numfmt first due to the additional features and less restrictive license.
function format(pattern: string, value: any, options?: {
dateErrorNumber?: boolean;
dateErrorThrows?: boolean;
dateSpanLarge?: boolean;
fillChar?: boolean;
ignoreTimezone?: boolean;
invalid?: string;
leap1900?: boolean;
locale?: string;
nbsp?: boolean;
overflow?: string;
skipChar?: boolean;
throws?: boolean;
}): string;
The format function has an intimidating list of options. The most intriguing is leap1900.
Simulate the Lotus 1-2-3 1900 leap year bug. It is a requirement in the Ecma OOXML specification so it is on by default.
Hold tight, there’s a lot to unpack here.
Serial Dates
No, not the natural end result for monogamists with commitment issues. Serial dates are how spreadsheets represent dates (and times) using a single number. The number is interpreted as the number of days since some base date. Times are represented as fractions of days.
The original version of Excel for Mac came out in September 1985. It used a base date of 1904-01-01, which matched how MacOS represented dates at the time.
The first version of Excel for Windows was Excel 2 in October 1987. The leading spreadsheet product for PC was Lotus 1-2-3. It used a base date of 1900-01-00 (1900-01-01 is serial 1). To ensure compatibility with Lotus 1-2-3, the Windows version of Excel used the same base date. It was also bug for bug compatible, including treating 1900 as a leap year (it isn’t) and formatting serial 0 as 1900-01-00.
When Visual Basic was integrated into Excel 5 (released in 1993), it used yet another date system. VBA doesn’t reproduce the leap year bug. It uses 1899-12-30 as a base date so that its serial numbers are the same as Excel for dates from 1900-03-01 onwards.
Microsoft went all in on XML and open standards, switching from a proprietary binary format to an open format based on XML and ZIP. The format was published as the ECMA-376 standard in December 2005. This is the “Ecma OOXML” specification mentioned in the numfmt documentation. It requires implementations to support both the 1900 date base system (including leap year bug) and the 1904 date base system used on the Mac. There’s a date1904 flag per Workbook in the file format to tell you which to use.
The second edition of ECMA-376 came out in December 2008. It documents three date systems.
- A new default “1900 date base system” which uses the same approach as VBA. The base date is 1899-12-30 and 1900 is NOT a leap year. It also allows negative serial numbers, supporting dates before 1900 for the first time. The documented range is -9999-01-01 (serial -4346018) to 9999-12-31 (serial 2958465).
- “1900 backward compatibility date base system” (1900 is a leap year). Range from 1900-01-01 (serial 1) to 9999-12-31 (serial 2958465).
- “1904 backward compatibility date base system”. Range from 1904-01-01 (serial 0) to 9999-12-31 (serial 2957003)
An additional dateCompatibility flag in the file format is used to distinguish between the new and backward compatibility date systems.
Things stayed the same through the third edition in June 2011 before one final change for the fourth edition in December 2012. Now we’re back down to two date systems. The 1900 backward compatibility system has been removed. Strangely, the range for the default 1900 base date system was reduced so that it starts at 0001-01-01 (serial -693593). Maybe they decided negative years were meaningless, or no one ever implemented them.
This is the date system that Google Sheets uses. Naively, I assumed this meant that Excel on Windows had also finally aligned with VBA and got rid of the leap year bug and that Excel on Mac still had its own 1904 based date system. Neither is true.
Excel still treats 1900 as a leap year and still doesn’t support dates earlier than 1900-01-01. Microsoft says potential backwards compatibility issues mean its not worth fixing when the date is only wrong for Jan/Feb 1900. If you want to work with dates before 1900, Microsoft recommends that you write a VBA function to do it.
Excel on Mac has used the same date system as the Windows version for the last decade. The 1904 system is only supported for backwards compatibility with old versions of Excel.
I’m with Google Sheets and ECMA-376 on this one. We’re going to use the extended range, leap year bug free, ECMA standard, 1900 date base system. Serial values are aligned with Excel for every date apart from Jan/Feb 1900, which Excel clearly doesn’t care about anyway. We’ll eventually need to support import of Excel files. We can fix up dates during import processing if needed.
Formatting Options
The numfmt default options support extended range and the 1900 leap year bug. Which is weird because it’s a combination that Excel has never supported. If you want full Excel compatibility you need restricted range and leap year bug. If you want compatibility with Google Sheets, VBA and everything else, use extended range and no leap year bug.
I think the numfmt default is an attempt at achieving maximum compatibility. It aligns with Excel for dates from 1900-01-01 onwards. It even preserves Excel’s interesting behavior of formatting serial 0 as 1900-01-00. It aligns with the new ECMA date system for dates from 1899-12-29 and earlier. Which means that in addition to supporting the non-existent 1900-02-29 it doesn’t support 1899-12-30 and 1899-12-31 at all.
In case the defaults change in future I’m explicitly setting both options the way I want them.
const numfmtOptions = {
leap1900: false,
dateSpanLarge: true
}
Return of the World’s Most Boring Spreadsheet
It’s been 18 months since I first introduced you to the world’s most boring spreadsheet. At one million rows and ten million cells it’s right at the limits of what Excel and Google Sheets allow.
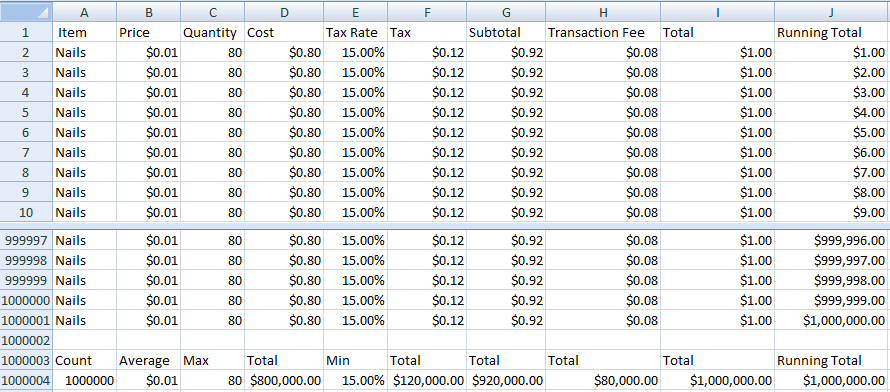
I’ve finally reached the point where I can implement it, albeit for display purposes only. To make things more interesting, I’ve added two new columns that record the date and time for each purchase. The hardware store has an online presence now, with a new sale hitting the live spreadsheet every minute.
Try It!
Boring Data
The implementation is almost as boring as the data itself. The main cell values are defined by :
const serialDate = baseDate + row / (24*60);
switch (column) {
case 0: return serialDate;
case 1: return serialDate;
case 2: return "Nails";
case 3: return 0.01;
case 4: return 80;
case 5: return 0.80;
case 6: return 0.15;
case 7: return 0.12;
case 8: return 0.92;
case 9: return 0.08;
case 10: return 1.00;
case 11: return row;
}
The totals row at the end is :
switch (column) {
case 0: return baseDate + 1 / (24*60);
case 1: return baseDate + count / (24*60);
case 2: return count;
case 3: return 0.01;
case 4: return 80;
case 5: return 0.80 * count;
case 6: return 0.15;
case 7: return 0.12 * count;
case 8: return 0.92 * count;
case 9: return 0.08 * count;
case 10: return count;
case 11: return count;
}
The most interesting thing is that the cell values are simple numbers and strings, as they would be in a real spreadsheet. The formatting is doing most of the work :
getCellFormat(snapshot: number, row: number, column: number) {
if (row == snapshot + 3 && column == 1)
return "yyyy-mm-dd";
switch (column) {
case 0:
return "yyyy-mm-dd";
case 1:
return "hh:mm";
case 6:
return "0%";
case 3:
case 5:
case 7:
case 8:
case 9:
case 10:
case 11:
return "$0.00";
default:
return undefined;
}
}
Next Time
Now that I have some plausible looking data in my spreadsheet, I’m itching to start changing it. Next time, we’ll make a start on supporting editing.