As ever I’m spending the week after re:Invent gorging on YouTube videos at 1.5x speed. This year I’m trying to use my time as efficiently as possible. I want to find more nuggets of gold and less corporate filler.
I thought that the AWS Top Announcements of Reinvent 2024 Blog might be the short cut I’m looking for. It has a long list of product announcements but nothing about the technical sessions I’m interested in. There’s also no mention of Aurora DSQL which was the most interesting announcement of the week.
The official AWS on-demand sessions site is hopeless for finding your way through. Just links to YouTube play lists with lots of sessions missing. Nothing beyond the session title to go on. Unofficial session planners are far better at letting you filter the catalog to find something interesting, then search for the title on YouTube yourself.
Keynotes
I like to start with the keynotes to get a sense of the overall vibe. This year I’m down to two keynotes. The CTO keynote is always thought provoking and worth watching. The CEO keynote has all the most significant announcements. It’s worth fast forwarding through the filler to get a list of candidate topics to go deeper on.
CEO Matt Garman
I didn’t need to fast forward through the filler. AWS helpfully have a Keynote highlights in 10 minutes video. Seven minutes later and I have my list of candidate topics.
- Trainium2 UltraServers
- Apple Customer Segment (Apple publicly admitting they use AWS!)
- Trainium3 next year
- S3 Tables
- S3 Metadata
- Aurora DSQL
- JPMorgan Chase Customer Segment
- Amazon Nova AI models (with Andy Jassy, Amazon CEO)
- Amazon Q Developer agents for generating unit tests, documentation and code reviews
- Amazon Q Developer automated porting of .Net code from Windows to Unix
- Amazon Q Transform for VMWare - port VMWare to native cloud
- Amazon Q Transform for Mainframe - port mainframe applications to native cloud
- PagerDuty customer segment
- Amazon Q Business automation for complex workflows
- Next Gen Amazon SageMaker (rebranding lots of stuff as SageMaker)
CTO Werner Vogels
As always the keynote opens with a lengthy prerecorded video segment. This year it’s a mockumentary on the origins of S3. The overall theme is looking back over 20 years at AWS.
Introduction
- Have updated last year’s thefrugalarchitect.com - Simple laws for building cost-aware, sustainable, and modern architectures.
- Everything fails, all the time, so plan for failure
- Keep it simple - systems tend to become more complex over time as you crowbar features in
- “Simplexity” - Simplicity principles for managing complex systems
- Tesler’s law - Complexity can neither be created nor destroyed only moved somewhere else
- Intended vs Unintended complexity
- Warning signs
- Declining feature velocity
- Frequent escalations
- Time-consuming debugging
- Excessive codebase growth
- Inconsistent patterns
- Dependencies everywhere
- Undifferentiated Work
- Example - customers having to deal with eventual consistency in S3. Moved complexity into S3 by implementing strong consistency for them.
- Simplicity requires discipline
- Canva Customer Segment - Planning for scale: Monolith with internal service model that could be easily sharded into microservices when needed
- Lehman’s laws of software evolution
- Continuing Change - systems must be continually adapted else they become progressively less satisfactory
- Continuing Growth - The functional content of a system must be continually increased to maintain user satisfaction with the system over its lifetime
- Increasing Complexity - As a system evolves its complexity increases unless work is done to maintain or reduce it
- Declining Quality - A system will be perceived to be declining in quality unless it is rigorously maintained and adapted to its changing operational environment
Lessons in Simplexity
- Make evolvability a requirement
- Modeled on business concepts
- Hidden internal details
- Fine-grained interfaces
- Smart endpoints
- Decentralized
- Independently deployable
- Automated
- Cloud-native design principles
- Isolate failure
- Highly observable
- Multiple paradigms
- Example: Amazon S3 from 6 microservices to 300+ behind backwards compatible API
- Break complexity into pieces
- Example: CloudWatch - started as simple metadata storage service, got very complex over time, anti-pattern: Megaservice
- System disaggregation
- Low coupling / high cohesion
- Well-defined APIs
- Example: Modern Cloudwatch has many separate components behind frontend service. Individual components rewritten from C to Rust
- How big should a service be?
- Extend existing service or create a new one?
- Can you keep an understanding in your head?
- Align organization to architecture - Andy Warfield (Distinguished Engineer) on how architecture/organizational complexity is managed in S3
- Build small teams, challenge the status quo, encourage ownership
- Your organization is at least as complex as the software
- Successful teams worry about not performing well
- Constructively challenge the status quo
- Have new team members include a Durability threat model in their new feature designs
- Focus on ownership
- Effective leaders ensure teams have agency and so a sense of ownership
- Effective leaders drive urgency
- Organize into cells
- Cell based architecture
- Shard microservice into cells
- Reduce the scope of impacts
- Shuffle sharding to map customers to cells
- Partitioning strategy + Control plane
- Cell should be big enough to handle biggest workload required, small enough to test at full scale
- Time to build service is insignificant compared with time you’ll be operating it
- In a complex system, you must reduce the scope of impact
- Design predictable systems
- Constant work principle
- Example: Pushing config changes to fleet of workers. Instead of doing live, with unpredictable amount of work for different workers, write config to file in S3, then all workers pull latest config from S3 on a schedule and apply everything.
- Reduce the impact of uncertainty
- Automate complexity
- Automate everything that doesn’t need a human in the loop
- Automation is the standard approach, human step is the exception
- Example: Automating threat intelligence inside AWS
- Automation makes complexity manageable
- Looking at automating support ticket triage with AI
- Automate everything that doesn’t require human judgement
Aurora DSQL
- Database Complexity Burden
- EC2 -> RDS -> Aurora -> Aurora Serverless and Unlimited -> Aurora DSQL
- Multi-region strong consistency with low latency, Globally synchronized time
- Implemented as hierarchy of independent distributed components following Simplexity principles
- Rattles quickly through DSQL architecture
- Firecracker VM vital building block for managing Postgres session state in a serverless way
- Each Postgres session/connection has a dedicated Firecracker micro-VM running the Postgres engine
- For interactive sessions (human user in the loop), the VM can be suspended and then rehydrated and resumed
- Simplification of distributed systems if you have accurate, globally synchronized time
- Single microsecond accuracy
- Each timestamp has an error bound, ClockBound library for working with bounded timestamps
- Also used in DynamoDB global tables with strong consistency
- Have added time as a fundamental building block you can use to simplify your algorithms
Product Launches
Let’s look at the most interesting product launches highlighted in the keynotes.
Generative AI
Like last year, there’s no end of generative AI buzzwords. Maybe I’m too old to learn new tricks, but I’m simply not interested. When they wheel out Andy Jassy to make the big announcement and all he can say is that their new Nova models are not quite as good as the competition but cheaper, I know there’s nothing worth looking at.
Aurora DSQL
There were two technical breakout sessions on Aurora DSQL, both from Marc Brooker. The first thing addressed in both sessions was the name. Clearly the marketing department won out. This is a brand new database with its own characteristics, not another flavor of Aurora.
The two craziest things are that DSQL is faster (in a multi-region setup) when you use transactions heavily and the less data locality you have. Both are the opposite of the conventional wisdom when using relational databases.
Get Started with Amazon Aurora DSQL
The focus in this session is how to build your stuff on top of DSQL. The key takeaway is how easy it is. This is Werner’s simplexity in action. The database is doing all the hard stuff so even a multi-region active-active setup is easy.
Introduction
- Serverless Postgres compatible relational database optimized for transactional workloads
- Started in January 2021
- Scalable up and down
- Serverless like DynamoDB and S3 are serverless (not like all those AWS products with serverless in the name that can’t scale to zero)
- In multi-region setup no compromise on consistency, isolation, ACID properties
- Postgres compatible - cover “most” of PostgreSQL surface area
- Small single region application
- DNS -> ALB -> App Server -> Regional DSQL Endpoint
- Thousands of requests per second, 99.9% availability with ASG, no data loss on failover, easy to add more app servers
- Serverless application
- Lambda Function URLs -> Lambda Function -> Regional DSQL Endpoint
- Tens of thousands of requests per second, 99.95% availability, no infrastructure
- Large single-region application
- DNS -> LB -> 3 x App stack per AZ -> Regional DSQL Endpoint
- Tens of thousands of requests per second, 99.95% availability, infrastructure depends on app stack used
- Avoid hot write keys
- Incrementing counter hit by lots of transactions
- Design schema so that you spread reads and writes across multiple keys
- Specific to writes, reads never conflict, read only transactions always commit
- Concurrent transaction conflicts. No read-write, write-read conflicts. Only write-write can conflict.
- Traditional DBs love data locality (performance from caching working set in server memory), DSQL loves dispersion
- Don’t have to worry at low scale - thousands of requests per second or less
Multi-region Active-Active
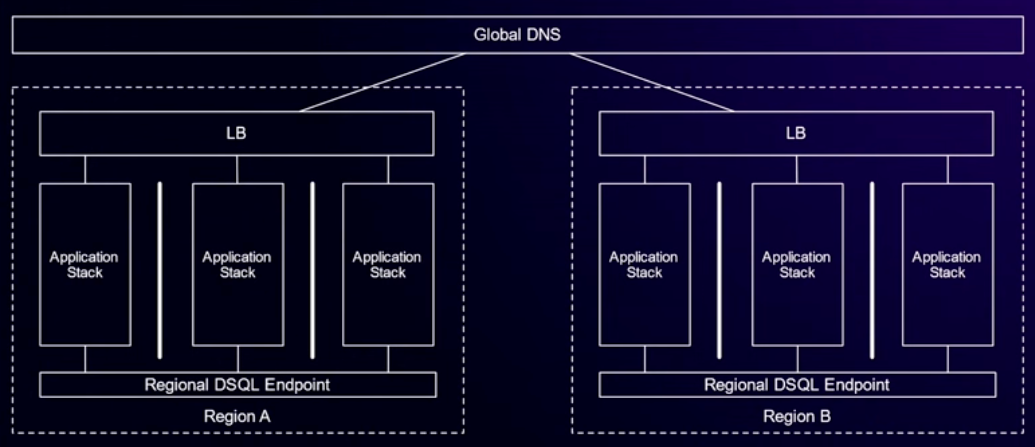
- Just taken single-region architecture and stamped it out in each region with Global DNS for request routing
- No inter-region connections needed at app level
- AZ failure: Availability impact milliseconds to seconds, no data loss, no consistency loss
- Region failure: Availability impact of milliseconds in remaining regions, time for global DNS to reroute for failed region and restart failed transactions, no data loss, no consistency loss
- Active-Active benefits: Caches/JITs are warm (compared with failover region), you know both sides work, easy capacity planning, route customers to closest region, DSQL offers symmetric latency (doesn’t matter which regional endpoint you speak to).
- Multi-region speed tips
- Reads are always in-region (including commits for read only transactions, reads in read-write transactions)
- Writes are always in-region
- Relies on clock architecture
- Read-write transaction commits cross regions - 15-100ms penalty depending on region configuration
- Transactions improve latency! - amortize cost of commit across multiple statements
- More keys in the transaction increases chance of conflict with another transaction, so don’t go mad
- Isolation and Consistency
- Snapshot isolation only for preview
- Strongly consistent (linearizable), even across regions, even for scale-out reads
- Together gives you “strong snapshot isolation”
- In most cases you shouldn’t have to worry about consistency in your app
- Equivalent to Postgres REPEATABLE READ, better than all MySQL isolation levels
- Only Postgres SERIALIZABLE is stronger
- Strong snapshot isolation is a sweet spot
- Serializable has big performance downsides which requires app programmer to write code that avoids problems
- No performance benefit for weaker isolation levels in DSQL
- Designing for scalability naturally gives you most of snapshot isolation for free
Deep Dive into Amazon Aurora DSQL and its architecture
This is the session that goes deep into the internal architecture of DSQL. There are five major layers, only one of which (the query processor) uses any code from Postgres. All the distributed systems work is AWS custom code, written in Rust of course.
I’ve been a fan of event sourced systems for a while. Guess what, DSQL is an event sourced system too.
- Focus on internals of DSQL, app programmer doesn’t need to know this stuff
- Rethinking transactional databases
- Event sourced system! - “the journal is the database”
- Built on internal AWS journal service - atomic and durable for free
- Adjudicator service looks for conflicts with other recently committed transactions (since this one started) before writing to journal - isolated
- Distributed commit protocol between adjudicators for scalability
- Key space distributed between adjudicators. Where they do have to collaborate on a transaction uses much improved version of two phase commit
- Need to index journal for efficient query. Storage provides efficient ways to query data. Not responsible for durability or concurrency control.
- Database rows are sharded across storage nodes.
- Multiple journals!
- Query processor - lots of query work pushed down to storage layer: simple get, filters, counts, projection
- Interactive transactions - multiple round trips from app to database during a transaction (possibly even interacting with user)
- Transaction and session router -> PostgreSQL Query processor running in Firecracker VM per connection
- CTO Keynote mentioned that Firecracker VM can be suspended and rehydrated for long interactive transactions (e.g. humans in the loop). Potentially scaling compute down to zero if no activity even with active transactions.
- Isolation of reads
- Depends on AWS time sync foundation
- Clock read at start of transaction
- Every query to storage includes “at time t” condition
- Storage nodes implement MVCC
- No coordination needed at all between query processors and storage nodes
- Not using Postgres implementation - new approach that avoids need for Vacuum
- Five layer architecture: Router, query processor, adjudicator, journal, storage with each layer scaling horizontally/independently/dynamically
- Scalability and resilience comes from avoiding coordination
- During transaction query processor reads direct from storage nodes that contain required data and buffers writes internally
- At commit time query processor interacts with adjudicators that own relevant key space which then write to a single journal. Storage engines that own modified data are notified and pull updates from the journal.
- Isolation deep dive
- No coordination before commit
- Optimistic concurrency control
- Transaction starts at Tstart, ends at Tcommit
- Transaction can commit if (and only if) no other transaction has written to the same keys between Tstart and Tcommit
- Writes are all performed at Tcommit
- Contract with adjudicator: Here are keys I intend to write + my Tstart, if no other transaction has written these keys since Tstart pick a Tcommit and write changes to the journal, never allow another transaction to pick a lower Tcommit.
- Multi-Region
- All about minimizing round trips between regions
- Only commits of write transactions need cross-region coordination. Need to check isolation rules and make data durable.
- Optimized for fast failover. Only place this matters is failover of adjudicator that owns a keyspace. Adjudicators have fixed size transient soft state, so easy to replace.
- Preview supports three region architecture. Two active regions with data storage, one journal only “witness” region. If there’s a network split, the active region on the same side as the witness region has a clear majority and can continue to be available. For large scale geography can put witness region in the middle to optimize for latency.
- Adjudicators spread across regions. Only one adjudicator for each range of keyspace.
- If region fails or is isolated, new adjudicators have to be started on the majority side.
- Region can use its existing QPs, journals and storage nodes for everything else. Journal and Storage are replicated. QPs only have transient state.
- Journal and Storage use existing internal components that are foundations for DynamoDB and Aurora. They already handle ordered replication across hosts, AZs, regions.
- ??? How do you decide which journal to write a transaction to?
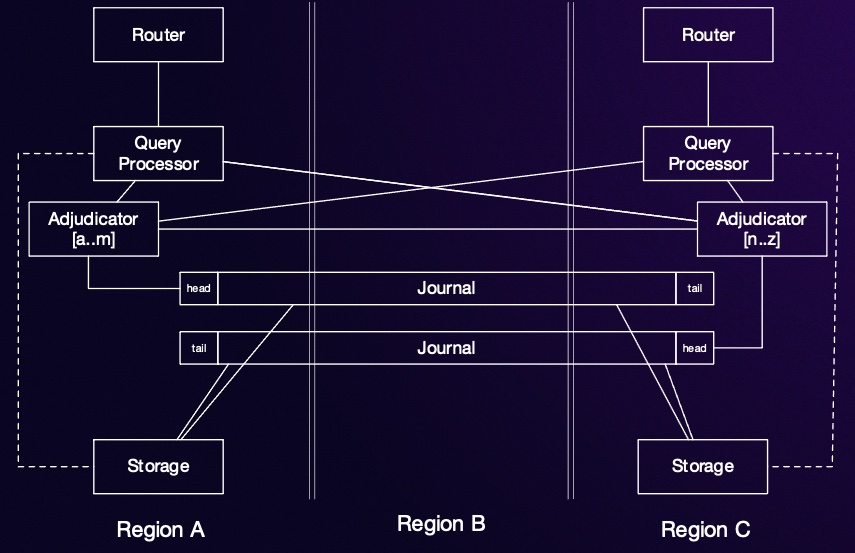
- Implementation Quality
- Built in Rust
- Deterministic simulation testing - effectively unit tests for distributed system behavior. Open source library “Turmoil” on GitHub.
- Fuzzing of SQL surface area, compare with results on RDS and Aurora
- Formal methods
- Runtime monitoring - compare runtime logs against formal specification to ensure that actual implementation matches formal spec
If you’re interested in more detail on DSQL internals, there’s more on Marc Brooker’s blog.
- Aurora DSQL and A Personal Story: Overview of DSQL and history of work that led up to it
- Reads and Compute: DSQL read path, avoiding need for cache in query processor
- Transactions and Durability: DSQL write path, only commited transactions written to journal, how storage nodes know they have all data from transactions committing before a given time
- Wait! Isn’t That Impossible: Multi-region architecture
- MemoryDB: Speed, Durability, and Composition: More details about the Journal service in the context of its use in MemoryDB
S3 Tables
I watched Store tabular data at scale with Amazon S3 Tables to understand whether S3 tables is a feature I might use in future. S3 tables is basically some optimizations and automated management that make it easier and more efficient to use Apache Iceberg with S3. Apache Iceberg is a data format for S3-like blob stores that provides table semantics for large analytic datasets.
Iceberg builds on the foundations of the Parquet column-oriented data file format. Iceberg adds a tree of immutable metadata files above the data files. Each write operation adds a new set of data files and metadata files that represent the change, referencing the unchanged files from the previous snapshot. The principles are the same ones that I plan on using for my super scalable cloud hosted spreadsheet.
If you need more background on Iceberg :
- Ultimate Directory of Apache Iceberg Resources
- The Life of a Read Query for Apache Iceberg Tables
- The Life of a Write Query for Apache Iceberg Tables
- How Apache Iceberg is Built for Open Optimized Performance
Now onto the summary of the talk.
- Customers already use S3 as a tabular data store - There are exabytes of Parquet objects in S3 today
- Organized in same way as files and folders
- Evolving schemas and maintaining consistency becomes complex
- New open table formats have arrived, including Apache Iceberg
- Iceberg adds additional metadata files that enable higher level workflows
- Schema evolution, versioning of data, snapshots, multiple applications reading/writing common data set, SQL querying
- Challenges with use of Iceberg in standard S3
- Additional traffic to S3
- Hard to enforce table level security
- Operational burden of optimizing storage cost (compacting, removing redundant snapshots)
- S3 Tables is fully managed Iceberg tables
- New S3 table bucket type
- Tables are first class AWS resource (each table has an ARN, can apply policies to it)
- Dedicated tables API endpoint (CRUD on tables, update and commit changes)
- Maintenance policies for table management - compaction configuration, lifetime for snapshots
- Each table has its own S3 location that applications can use to read/write data and metadata files
- File deletes and overwrites are blocked - use the table APIs and maintenance policies
- Optimized performance
- 10x transactions per second, 3x query performance
- Using standard S3 APIs to read/write but S3 is aware that this is a table bucket and tunes for that
- Tweaks to S3 namespace to lay out data more optimally - optimized for iceberg key naming
- Capacity provisioned for higher throughput than general purpose bucket
- Iceberg optimizations on client side tuned for S3
- Automatic Compaction
- Compaction consolidates many small data files into larger ones
- Previously customers would have to spin up their own compute to run the compaction
- S3 tables runs compaction automatically in the background. The 3x improvement is compared against unmanaged tables that have never been compacted.
- Security Controls
- Previously had to apply policies to underlying data and metadata objects - had to understand structure
- Now just apply policy to the overall table
- Can create namespaces to group tables and apply policy per namespace
- Cost Optimization
- Each commit adds a new set of data files as a snapshot
- Previously needed to run procedures to expire old snapshots, remove unreferenced files
- Now automated
- Usage
- S3 Tables is a storage primitive
- To query/load data use AWS analytics tools like EMR, Athena, Redshift, Data Firehouse via AWS Glue
- S3 Tables automatically registered with AWS Glue which acts as your Iceberg data catalog
- Fine grained access control for specific rows/columns via AWS Lake Formation
- S3 tables catalog for Iceberg is a plugin that allows third party Iceberg compatible applications (e.g. Spark) to discover and access your data
- Use Cases
- Real-time analytics: Data Firehose -> S3 Tables -> Quicksight
- S3 Metadata Tables
S3 Metadata Tables
S3 Metadata Tables is the other new S3 feature announced at re:Invent. It’s built on top of S3 Tables. I watched Unlock the power of your data with Amazon S3 Metadata.
- Customer metadata stores have to live outside of storage - difficult to build, operate, scale, keep consistent
- Automatically generate rich metadata for every object in your S3 buckets
- Accessible with simple SQL semantics
- Includes system metadata, object tags and user-defined metadata
- Stored in an Iceberg table in an Amazon S3 table bucket
- Metadata generated in “near real-time” as content of your S3 bucket changes
- Journal table - “system table” for your bucket, AWS managed, change events, read only
- 21 system metadata fields - e.g. object size, storage class, create date, object tags
- Can be queried using lots of AWS and open source analytics tools
- Custom metadata - use S3 object tags and user-defined metadata to get custom stuff
- Can create your own tables in table bucket (e.g. using Lambda to process new S3 objects) and join with journal table
Technical Talks
As well as the new product launches, there’s a rich variety of technical talks at re:Invent. Unfortunately, the good stuff can be hard to find. Over the years I’ve come up with a system to narrow down the field.
I’m a fan of the Builder’s Library AWS technical articles. The first thing I do is filter the list of sessions based on the authors of Builder’s library articles. These people are the technical thought leaders at AWS, usually with a VP and Distinguished Engineer job title. This year I found sessions by Marc Brooker, Colm MacCarthaigh, Becky Weiss and David Yanacek. Then I further filter to focus on 300 and 400 level talks to get a final list of candidates.
Failing without flailing: Lessons we learned at AWS the hard way
This session has three speakers, including Becky Weiss, building on 5 things you should know about resilience at scale from last year.
Persistent connections
- Consider Horizontal distributed system that scales up when it needs more capacity
- Has front end service connecting to authentication service
- When an instance in authentication service fails, the frontend services switch over to the healthy instances
- Connection overhead is expensive so front end service will prefer to use persistent connections
- What happens after connection fails when destination authentication instance goes bad?
- Connection can get stuck with some messages in indeterminate state. Usual pattern is that a watchdog process on frontend notices and restarts the stack
- As scale increases this becomes more and more of a problem
- Hypothesis: An application’s resilience is, in part, proportional to how often its recovery workflows are executed
- Naive architecture with a fresh connection for every message is much more resilient …
- Best middle ground is to regularly recreate connections. Have a maximum lifetime, for example a few minutes.
- Takeaways: Resilient systems embrace and expect failure at all layers. The most resilient workflows are ones that happen all the time as part of normal operations. Connection management is a good indicator of how well a service team thinks about resilience.
Is it a problem or a deployment?
- load balancer -> app servers -> AWS storage backend
- What if app servers have state? e.g. cache
- When an app server is replaced, it takes a significant amount of time to ramp up and be able to handle full share of load
- Long winded example from 10 years ago of how this caused problems for DNS within EC2, resolving DNS queries for other EC2 instances within a VPC
- Fleet of DNS servers, each with significant amount of state
- Updates to DNS being propagated from DNS control plane to DNS hosts
- When a new DNS host spins up, needs to do a full sync of state which takes a long time
- If you graph time from EC2 launch to it being resolvable via DNS, it jumps up during a DNS deployment, then normalizes once state has propagated
- During deployment this looks the same as a real problem. You assume it’s just the deployment and everything will go back to normal …
- Had a bad deploy which led to prolonged degradation because the team were waiting for everything to go back to normal and it didn’t. Long delay before they finally rolled back.
- Short term fix was focus on DNS host startup time - optimize to get it under the 30 seconds it then took to get an EC2 instance up and running
- Other techniques for stateful hosts: Download snapshots of state, control max size of state with cellular architecture, pre-warm cache, send host synthetic traffic to warm up connection pools
Measuring bottlenecks
- Example from VPC
- Control plane and data plane architecture
- Distribute state from control plane to data plane
- Uses append only queue which data plane reads from
- Also writes pre-computed state to reduce work needed by data plane
- Pre-computation process means that updates aren’t independent any more. If two control plane instances are writing to the queue, the second one has to take account of what the first one wrote.
- Had to add a lock. Critical section is read existing state, compute new state, write to end of log.
- As system scales up, you reach a state where rate of arrival saturates the lock. Requests timing out because they couldn’t acquire lock.
- Ran into this problem after update with new feature that slightly increased length of critical section.
- Wanted to add metrics to see how much headroom was left
- Sum up critical section time over a time window. Alarm at some point before the sum is the entire time window
- Little’s law is generalized version of this: avg(concurrency) = avg(arrival-rate) * avg(latency)
- Right hand side for fixed time window is n * (sum(latency) / n) which is sum(latency)
- For a lock, max concurrency is 1. Little’s law applies more generally. e.g. If you have pool of workers can use Little’s law to predict how many workers you’ll need, or how close you are to running out of headroom.
- Takeaway: Sum(latency) is a really easy metric to measure concurrency over time
Cheap tricks for faster recovery
- If you log count of rarely seen errors, also log 0 if you haven’t seen any errors in that logging interval. Makes it easy to see if whatever you’ve done has fixed the problem. Also means you can tell if system is in such a bad way that its stopped posting metrics at all.
- Graph by instance id makes it easy to see if you can mitigate problem immediately by killing problem instance
- Turn it off and on again. Assuming you restart regularly and have high confidence, first response to any problem is to restart, then figure out what the root cause is.
Thing big, build small: When to scale and when to simplify
Colm MacCarthaigh talking about general approaches you can use to ensure that you architect whatever you’re building at the right level of scale and complexity.
I was a little disappointed with this one. The guidance is very high level and I didn’t learn anything new.
Small Architecture
- Making an existing system smaller and less complex is great if you can do it but not always possible
- Smaller is more understandable, easier to make reliable and secure
- Architecting for small
- Application architecture: Structure for efficiency, Monolith vs micro-services, common cloud architectures
- Organizational architecture: How to promote and reward economy, measure outcomes, align incentives, being data driven
Iterative Architecture
- Not just up front design in your ivory tower
- First take on architecture is usually wrong
- Need to decide what success looks like, measure constantly, adapt and iterate based on feedback
- Prototype, Test, Monitor, Improve, Repeat
Integrating Costs
- Understand costs as soon as possible
- Teams should know how much they are spending
- Per-unit costs analyzed weekly is a good standard (e.g. cost per request)
- Usually cost of developers is more significant - particularly opportunity cost
- Need a rigorous prioritization process. What cans can be kicked down the road?
- Example: Choosing a programming language. Evaluating Rust vs Go as a C replacement.
- Driver for decision was developer and opportunity cost. More chance of attracting Rust rock stars as first big company to go all in on Rust.
- Example: Monolith vs micro-services
- Do performance requirements demand tightly coupled code?
- What’s the opportunity cost of having dev teams blocked on each other?
- How do we monitor and measure changes to those answers over time as system iterates?
- Example: We need to re-architect!
- Why? What cliff are we running off? How far away is it?
- How quickly can we measure improvements of next architecture?
- Can we put a monetary value on that?
- Not re-architecting for the sake of it
Common cloud patterns
- High Availability
- Most common type of cloud workload
- Deploy to two or more AZs for redundancy
- Best way to be more efficient is to use more AZs
- With two AZs have 100% overhead to allow for single AZ failure. With three it’s only 50%.
- Best effort
- No redundancy or resilience
- OK to restart if there’a a failure
- Single AZ or multi-AZ without redundancy
- Non-latency sensitive, non-critical systems
- Common for machine learning training - not affordable to have extra redundancy
- Savings from most efficient hardware and network, optimizations in how you use AWS
- Highly isolated systems
- Isolated, often single-tenant environment
- Highly-regulated and critical workloads with top-to-bottom change control and long testing cycle
- Trading exchanges, critical government systems
- Dedicated AWS local zones and outposts
- Cost management is about right-sizing
- Traditionally focused on 100% availability for 40 hour working week
- Moving from 40 hour to 24/7 can drive larger system efficiencies
- Globally distributed
- Multi-region and edge applications
- Failover architectures can require 3X or 4X footprint
- 2 AZs in primary region, 1-2 in failover region
- Active-Active is cheaper and best for end-user latency
Culture
- Open book finance and awareness of costs
- Avoid “not invented here”
- Celebrate wins
Try again: The tools and techniques behind resilient systems
Marc Brooker again, talking about how to handle failures. This is may favorite talk from re:Invent. Lots of actionable insights and things that I should have known but didn’t.
Rethinking retries
- Web client configured with timeout, max retries, exponential backoff and jitter
- Server where Latency is proportional to currency (modelled as A + B * concurrency)
- Baseline load comfortable for system + one second spike of overload
- If no retries configured client sees outage of 1-2 seconds where requests fail and then back to normal within twice length of spike
- Now try it with the 3 retries - client sees outage and system never recovers!
- Client retries cause 4X traffic …
- This kind of thing is behind most large scale failures seen in the field. System gets in bad way and enters doom loop where more load is piled on.
- Two kinds of failures: Transient failures caused by individual component failures where retries help, system failures caused by load/correlated behavior/bugs/etc where retries are harmful.
- AWS uses adaptive retries (token bucket) to avoid these issues
- Each client has a token bucket for retries. Any time it does a retry it consumes a token from the bucket, any time a call succeeds it adds 0.01 tokens to the bucket
- Result is that for a stable set of clients load during an outage is capped at 101% of the usual load, compared to 400% for 3 retries without token bucket
- Eliminates whole class of metastable failures
- Behaves exactly the same as before if your transient failure rate is below 1%.
Open vs Closed System
- Idea of Open and Closed systems comes from classic distributed systems paper
- Open system: New work comes in from somewhere external, system has no control over rate at which it arrives. e.g. Web server.
- Closed system: Work generated from within the system. e.g. Pool of workers processing jobs for server.
- Asking caller to backoff has almost no effect on rate of work coming in for open system, but very effective for closed systems
- Jitter always a good idea
- Need to choose retry/resilience method appropriately depending on type of system
- Some systems can have mix of open and closed behavior
Circuit Breakers
- Lots of different definitions
- Boils down to mechanisms for deciding whether to try a request at all or reject it out of hand
- Two types: “Reducing Harvest” where non-essential functionality is sacrificed for availability, “Rejecting Load” where availability is sacrificed in the hope that it will reduce contention
- Most appropriate algorithms different for the two cases
- Have to be careful with sharded systems. System with four shards where one shard goes down. Client sees 25% failure rate. If it flips circuit breaker you’ve turned 25% failure rate into 100% failure rate.
- Can expand blast radius in microservice architectures. API server with APIs A, B, C and D internally implemented by microservices. If C fails, naive circuit breaker on client of API server sees 25% failure rate and blocks access to A, B and D too.
- Avoid on/off circuit breakers, prefer algorithms that adapt to downstream capacity like additive increase multiplicative decrease in TCP
- Successful circuit breakers might need to know internal details of downstream service (yuck)
Tackling tail latency
- Examples based on data from real AWS web service with mean latency 1ms, P99 2.5ms, P99.99 8.5ms
- Actually a really fast service with much better tail latency (8X) than most
- What can we do to reduce impact of tail latency?
- Send two requests and use first response to come back. P50 no change, P99 40% lower, P99.9 66% lower but double request volume
- Hedging. Send one request. If it doesn’t come back soon, send another. Use first result. Set threshold so that extra request sent at P90 latency.
- P50 no change, P99 17% lower, P99.99 54% lower at cost of 10% extra traffic
- Problem is that this introduces metastable failure modes
- If service under pressure and responses slow down, client will make extra request more often, potentially every time
- Can fix with token bucket but getting fiddly
- Erasure coding. Not general solution, only works with storage systems and caches.
- Idea has been used within storage systems, like RAID arrays, for 50 years.
- Store data with some redundancy so that if a drive fails you can reconstruct from remaining drives.
- Can extend across the network. Arrange things so you make N requests for data and can assemble response from the first k to come back. Cost is N times the request rate, N/k bandwidth, N/k storage (which you might need anyway for durability)
- Makes more sense for bandwidth/throughput constrained systems than request constrained
- Constant work (same effort for failure and success cases)
- Super effective at reducing tail latency
- Easy to tune N and k to meet needs of your system
- Used in many AWS services including container loading system in AWS Lambda
- As well as general tail latency benefits also see improved resilience. Can handle failed server or in-progress deployment
- Lambda uses a simple 4-of-5 code (just XOR, equivalent to parity drive in RAID)
What is metastability?
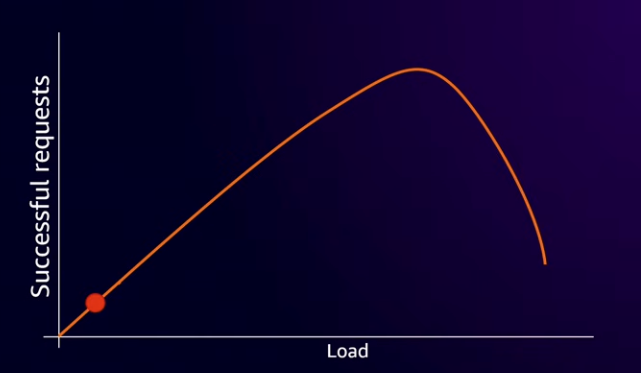
- Almost all systems have an inverted U shaped curve of successful requests vs load. At low loads the number of successful requests scales linearly with increasing load. Eventually system becomes overloaded and the number of successful requests starts to go down due to increased contention.
- Bad place to be. Would like reduction in load to move state back to the left with more successful requests.
- For most systems, like initial 3X retry example, that’s not what happens. Have to drop load right down to get it back to normal. For retry example need to get to 30% of normal load.
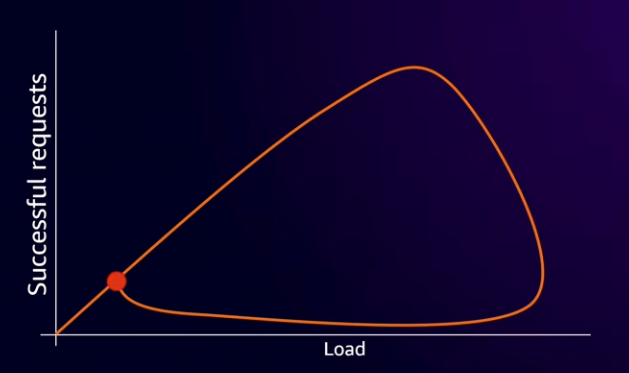
The open area inside the graph indicates metastability.
Simulation: Understanding behavior
- Intuition for how systems behave is usually wrong
- Could try and do the math to analyze behavior but needs good math knowledge
- Much simpler to run a simulation
- For 4-of-5 analysis above used resampling. Take real world measurements of latency. Pick 5 samples, write down 4th best. Repeat a lot of times and measure the results. Three lines of python.
- For 3X retry system took 150 lines of python. Code is super simple, directly models behavior of system, easy to write, review and understand.
- Another example, Nudge algorithm for improving latency in first come first served work queueing system. Rather than implementing in real system and then using metrics to see if it improves things, write a simulation. Much quicker, much less risk.
- Can use gen AI to create simulation for you from high level written description