Last time we discovered that it’s relatively easy to build a Grid View application using a Normalized Relational Database. True, it was a toy example with a small number of fixed fields. However, given some reasonable functional limitations, we showed how it could scale to manage large collections with 100,000 items or more.
Now we’re going to up the ante, and add support for custom fields. The requirements say we need to support multiple types of field (text, number, date, enum, … ) and potentially hundreds of fields. Each project can have a different set of custom fields.
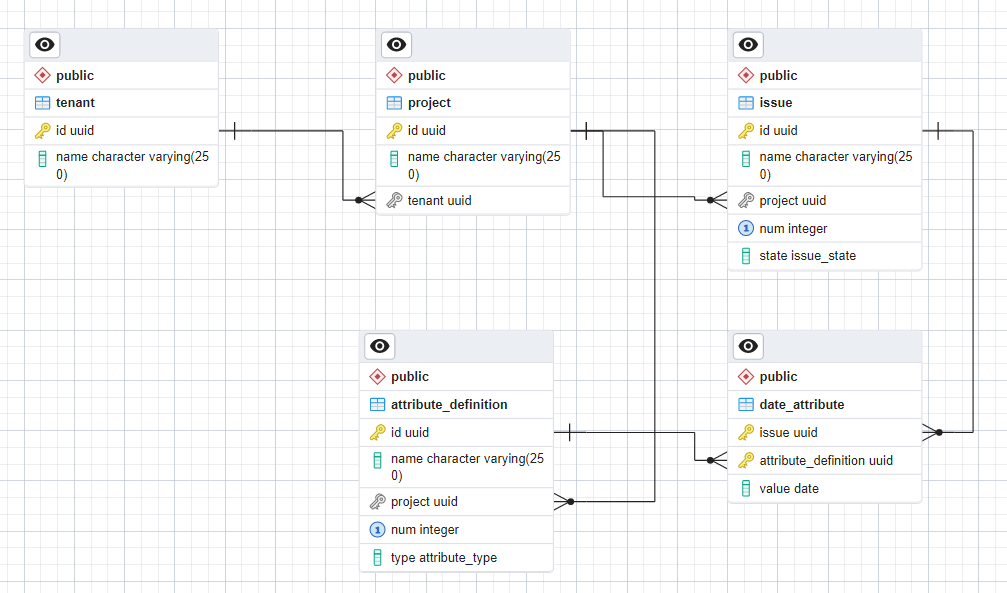
Here’s the schema from last time with two new tables added. Notice that we didn’t need to touch the original tables. To keep things simple, I’m starting by adding support for custom date fields. I’ll explain how to extend to other types as we go.
Schema
There are two new tables: attribute_definition and date_attribute. There is a many:1 relationship between attribute definitions and projects, while the date_attribute table has many:1 relationships with both attribute definitions and issues.
The attribute_definition table is used to define the custom fields in use on a project. Definitions are per project, enforced with a foreign key constraint. Each definition has a name, type and num. The type field is modeled as a Postgres enum and for now the only supported value is “date”. The num field is used to define an ordering so that the GUI can add columns to the grid view in the right order for each custom field. Just like for issues, I added a UNIQUE constraint on (project,num).
Each project can have different numbers and types of custom field. As usual with normalized design, any form of variability is handled by creating additional tables. The values of all custom date fields are stored in the date_attribute table. As well as storing the value, each row has foreign key constraints which specify which attribute definition this is a value of and which issue has this value for this definition.
The most interesting thing is that date_attribute does not have an explicit id column. I’m using a composite key of (issue,attribute_definition) for this table. Each issue can only have one value for each attribute definition. This is a case where there’s really no need to define another surrogate key.
Sample Data Set
Here’s the sample data set from last time updated with examples for the two new tables.
tenant
| id | name |
|---|---|
| 0807 | ACME Engineering |
| 3cc8 | Big Media |
project
| id | name | tenant |
|---|---|---|
| 35e9 | Forth Rail Bridge | 0807 |
| 7b7e | The Daily News | 3cc8 |
issue
| id | name | project | num | state |
|---|---|---|---|---|
| 020e | Needs Painting | 35e9 | 1 | open |
| 3544 | Launch new newspaper! | 7b7e | 1 | closed |
| 67d1 | Check for rust | 35e9 | 2 | closed |
| 83a4 | Hire reporter for showbiz desk | 7b7e | 2 | open |
| af34 | Girder needs replacing | 35e9 | 3 | open |
attribute_definition
| id | name | project | num | type |
|---|---|---|---|---|
| 3812 | start | 35e9 | 1 | date |
| 882a | end | 35e9 | 2 | date |
No surprise that it’s the engineering firm that are first off the mark making use of the new custom fields feature. They’ve defined a couple of date fields to capture the start and end date for each issue.
date_attribute
| issue | attribute_definition | value |
|---|---|---|
| 020e | 3812 | 2023-05-01 |
| 020e | 882a | 2023-06-01 |
| 67d1 | 3812 | 2023-05-02 |
| 67d1 | 882a | 2023-06-02 |
They’ve added start and end dates to two of their existing issues but haven’t bothered adding them to the remaining issue. This schema makes it very low cost to add a new custom field. Values for existing issues can then be added incrementally as needed.
Access Patterns
As before, I’m going to focus on querying issues within a project. The core query needs to retrieve issues in a specific project including custom field values for each issue. The simplest way of doing this is to use a LEFT JOIN between the issue and date_attribute tables. Using a left join ensures that we also return issues that don’t have any attributes defined.
SELECT * FROM issue LEFT JOIN date_attribute ON (data_attribute.issue = issue.id)
WHERE issue.project = '3fe9';
which results in
| id | name | project | num | state | issue | attribute_definition | value |
|---|---|---|---|---|---|---|---|
| 020e | Needs Painting | 35e9 | 1 | open | 020e | 3812 | 2023-05-01 |
| 020e | Needs Painting | 35e9 | 1 | open | 020e | 882a | 2023-06-01 |
| 67d1 | Check for rust | 35e9 | 2 | closed | 67d1 | 3812 | 2023-05-02 |
| 67d1 | Check for rust | 35e9 | 2 | closed | 67d1 | 882a | 2023-06-02 |
| af34 | Girder needs replacing | 35e9 | 3 | open |
This includes all the data we need but is horribly verbose. There is a separate row for each custom field defined for an issue, with the fixed fields duplicated. Ideally our API will return results that look more like
| id | name | project | num | state | start | end |
|---|---|---|---|---|---|---|
| 020e | Needs Painting | 35e9 | 1 | open | 2023-05-01 | 2023-06-01 |
| 67d1 | Check for rust | 35e9 | 2 | closed | 2023-05-02 | 2023-06-02 |
| af34 | Girder needs replacing | 35e9 | 3 | open |
We could post-process the results from the database query to get them in the right form but that will make it hard to paginate. Much better if we can get the database to return the records in the form we want.
The most direct way of doing this is to specify the columns we want in the output and to join each attribute explicitly.
SELECT id,name,project,num,state,custom1.value AS custom1,custom2.value AS custom2 FROM issue
LEFT JOIN date_attribute AS custom1 ON (custom1.issue = issue.id AND custom1.attribute_definition = '3812')
LEFT JOIN date_attribute AS custom2 ON (custom2.issue = issue.id AND custom2.attribute_definition = '882a')
WHERE issue.project = '35e9';
This does make the query project specific. You need to use the attribute definitions for the project to build the query dynamically. Running the query results in
| id | name | project | num | state | custom1 | custom2 |
|---|---|---|---|---|---|---|
| 020e | Needs Painting | 35e9 | 1 | open | 2023-05-01 | 2023-06-01 |
| 67d1 | Check for rust | 35e9 | 2 | closed | 2023-05-02 | 2023-06-02 |
| af34 | Girder needs replacing | 35e9 | 3 | open |
You can order and paginate this result set in the same ways we looked at last time for the original fixed fields schema. You can easily extend this query to more attributes, and to different types of attribute stored in other tables, by adding additional LEFT JOIN clauses.
Explain yourself
At this point, you should be thinking “that looks like a really complex query. Is it efficient?”
Let’s have a look.
EXPLAIN SELECT id,name,project,num,state,custom1.value AS custom1,custom2.value AS custom2 FROM issue
LEFT JOIN date_attribute AS custom1 ON (custom1.issue = issue.id AND custom1.attribute_definition = '3812')
LEFT JOIN date_attribute AS custom2 ON (custom2.issue = issue.id AND custom2.attribute_definition = '882a')
WHERE issue.project = '35e9' ORDER BY num DESC;
I’ve added an ORDER by clause to the end of the query to see whether the query plan is suitable for pagination.
Nested Loop Left Join (cost=0.44..29.08 rows=1 width=548)
-> Nested Loop Left Join (cost=0.29..18.61 rows=1 width=544)
-> Index Scan Backward using issue_project_num_key on issue (cost=0.13..8.15 rows=1 width=540)
Index Cond: (project = '35e9'::uuid)
-> Index Scan using date_attribute_pkey on date_attribute custom1 (cost=0.15..8.17 rows=1 width=20)
Index Cond: ((issue = issue.id) AND (attribute_definition = '3812'::uuid))
-> Index Scan using date_attribute_pkey on date_attribute custom2 (cost=0.15..8.17 rows=1 width=20)
Index Cond: ((issue = issue.id) AND (attribute_definition = '882a'::uuid))
The query plan uses a nested join of issue with date_attribute for the first custom attribute, with the result of that joined to date_attribute for the second custom attribute. As we’re starting with the issue table, the database can use the (project,num) index to find the required project and then iterate through issues in num order. For each join, the database looks for attributes with the specified attribute definition and the current issue’s issue id. There will be at most one such row which can be found using the primary key index on (issue,attribute_definition).
If we have k custom fields, the cost to query a page is O(klogn) for each issue on the page, compared with O(logn) for the entire page with the original fixed fields query. Cost has increased by a large constant factor. There is some mitigation. Attributes are sorted by issue in the index. Queries for different attributes of the same issue should benefit greatly from the database’s disk page cache.
If all the attributes are clustered together in the index, why do we need to lookup each one separately? Is there a more efficient way to do this?
Aggregate Functions
It turns out that combining results from multiple rows is a common problem in SQL. SQL includes aggregate functions which compute a single result from multiple input rows. This can be used to write a query that pivots results from a column spanning multiple rows to multiple columns within a single row.
SELECT issue,
MAX(CASE WHEN attribute_definition='3812' THEN value END) custom1,
MAX(CASE WHEN attribute_definition='882a' THEN value END) custom2
FROM date_attribute GROUP BY issue;
This query groups together the date attribute rows for each issue and aggregates them. A CASE statement is used to define the contents of each result column by returning only values that match a specific attribute definition. Finally, the aggregate function MAX is used to combine the returned values for each column into one. The input to MAX in each case is a single value for the matching attribute and NULLs for the others.
The overall result is
| id | custom1 | custom2 |
|---|---|---|
| 020e | 2023-05-01 | 2023-06-01 |
| 67d1 | 2023-05-02 | 2023-06-02 |
You can then use that complete query as a sub-expression on the right hand side of a join with the issue table.
SELECT id,name,num,state,custom1,custom2 FROM issue LEFT JOIN (
SELECT issue,
MAX(CASE WHEN attribute_definition='3812' THEN value END) custom1,
MAX(CASE WHEN attribute_definition='882a' THEN value END) custom2
FROM date_attribute GROUP BY issue)
AS attribs ON id = attribs.issue
WHERE issue.project = '35e9' ORDER BY num DESC;
resulting in
| id | name | num | state | custom1 | custom2 |
|---|---|---|---|---|---|
| af34 | Girder needs replacing | 3 | open | ||
| 67d1 | Check for rust | 2 | closed | 2023-05-02 | 2023-06-02 |
| 020e | Needs Painting | 1 | open | 2023-05-01 | 2023-06-01 |
But is this any more efficient? Let’s look at the query plan.
Nested Loop Left Join (cost=0.29..97.73 rows=1 width=548)
Join Filter: (issue.id = date_attribute.issue)
-> Index Scan Backward using issue_project_num_key on issue (cost=0.13..8.15 rows=1 width=540)
Index Cond: (project = '35e9b60a-d4d0-47ce-b9bd-af0a961ea65c'::uuid)
-> GroupAggregate (cost=0.15..85.08 rows=200 width=24)
Group Key: date_attribute.issue
-> Index Scan using date_attribute_pkey on date_attribute (cost=0.15..67.20 rows=1270 width=36)
As expected we have a single join. The left side of the join can use an index to iterate through issues in the project in num order. For each issue, the database executes the right side of the join which looks up the date attributes for the issue using the (issue,attribute_definition) primary key index. The rows returned are aggregated into one which is then joined with the issue. This scales as O(logn) for each issue returned.
What happens when we add additional types of custom field? We will have to add an additional left join for each type of attribute that stores values in its own table. Still a win. We might have hundreds of custom fields but only have a handful of different field types.
Sorting by Custom Field
So far, all the examples we’ve looked at have sorted and paginated on fixed fields from the issue table. What happens if we try sorting on a custom field?
We’re going to need a new index. I added an index on (attribute_definition,value,issue) to the date_attribute table. That gives me issues in value order for any attribute definition.
Explicitly including issue in the index has two purposes. First, it’s now a covering index. The index directly returns the issue without needing to retrieve it from the indexed row in the date_attribute table. Second, it makes the index suitable for KeySet pagination. These custom fields can easily contain duplicate values, so I need an additional unique column to sort by. The only one I have available is issue id.
It’s a trivial change to the SQL to order by one of the custom fields.
SELECT id,name,num,state,custom1,custom2 FROM issue LEFT JOIN (
SELECT issue,
MAX(CASE WHEN attribute_definition='3812' THEN value END) custom1,
MAX(CASE WHEN attribute_definition='882a' THEN value END) custom2
FROM date_attribute GROUP BY issue)
AS attribs ON id = attribs.issue
WHERE issue.project = '35e9' ORDER BY custom1 DESC;
Which results in
| id | name | num | state | custom1 | custom2 |
|---|---|---|---|---|---|
| 67d1 | Check for rust | 2 | closed | 2023-05-02 | 2023-06-02 |
| 020e | Needs Painting | 1 | open | 2023-05-01 | 2023-06-01 |
| af34 | Girder needs replacing | 3 | open |
Unfortunately, the query plan doesn’t look great.
Sort (cost=10000000020.53..10000000020.53 rows=1 width=548)
Sort Key: custom1 DESC
-> Nested Loop (cost=0.26..20.52 rows=1 width=548)
Join Filter: (issue.id = date_attribute.issue)
-> Index Scan using issue_project_state_num_idx on issue (cost=0.13..8.15 rows=1 width=540)
Index Cond: (project = '35e9'::uuid)
-> GroupAggregate (cost=0.13..12.28 rows=4 width=24)
Group Key: date_attribute.issue
-> Index Scan using date_attribute_pkey on date_attribute (cost=0.13..12.19 rows=4 width=36)
The query as currently written can’t make use of the new index. One side of the join accesses issues by project, the other all attributes for an issue. We need to rewrite the query so that it can iterate through all values of one attribute in sort order. We can then join the previous query with that.
SELECT id,name,num,state,custom1,custom2 FROM date_attribute LEFT JOIN issue LEFT JOIN (
SELECT issue,
MAX(CASE WHEN attribute_definition='3812' THEN value END) custom1,
MAX(CASE WHEN attribute_definition='882a' THEN value END) custom2
FROM date_attribute GROUP BY issue)
AS attribs ON id = attribs.issue
WHERE attribute_definition = '3812' ORDER BY value DESC;
The query plan looks good. No explicit sort, using the new index to access issues in sort order.
Nested Loop Left Join (cost=0.39..31.34 rows=1 width=552)
Join Filter: (date_attribute.issue = date_attribute_1.issue)
-> Nested Loop Left Join (cost=0.26..18.97 rows=1 width=560)
-> Index Scan Backward using date_attribute_attribute_definition_value_issue_idx on date_attribute (cost=0.13..8.15 rows=1 width=20)
Index Cond: (attribute_definition = '3812'::uuid)
-> Index Scan using issue_pkey on issue (cost=0.13..8.15 rows=1 width=540)
Index Cond: (id = date_attribute.issue)
-> GroupAggregate (cost=0.13..12.28 rows=4 width=24)
Group Key: date_attribute_1.issue
-> Index Scan using date_attribute_pkey on date_attribute date_attribute_1 (cost=0.13..12.19 rows=4 width=36)
Unfortunately, the results are incomplete
| id | name | num | state | custom1 | custom2 |
|---|---|---|---|---|---|
| 67d1 | Check for rust | 2 | closed | 2023-05-02 | 2023-06-02 |
| 020e | Needs Painting | 1 | open | 2023-05-01 | 2023-06-01 |
Face palm moment. Of course issues that don’t have the attribute defined will be missing if we’re only considering issues in the date_attribute table.
There’s no great answer to this problem. You have three choices.
- Maybe your PM and UX will agree that it’s a better user experience to only shows issues with a value when sorting by a custom field.
- You could implement your app so that every issue has an explicit value for every custom field (even if it’s NULL). Which seems wasteful and not in the spirit of a normalized solution.
- Use a separate query to retrieve the remaining issues that don’t have the attribute defined.
There’s nothing more to be said if you go for either of the first two options. Let’s focus on the last option. We don’t have an index that can give us issues without the attribute defined (if we did we could just use option 2). Issues without the attribute defined would sort together, so we need to sort on a secondary unique column like num for pagination. We already have an efficient query that will do that, all we need to do is add a filter for where the attribute is NULL.
SELECT id,name,num,state,custom1,custom2 FROM issue LEFT JOIN (
SELECT issue,
MAX(CASE WHEN attribute_definition='3812' THEN value END) custom1,
MAX(CASE WHEN attribute_definition='882a' THEN value END) custom2
FROM date_attribute GROUP BY issue)
AS attribs ON id = attribs.issue
WHERE issue.project = '35e9' AND custom1 IS NULL ORDER BY num;
Which produces the expected result.
| id | name | num | state | custom1 | custom2 |
|---|---|---|---|---|---|
| af34 | Girder needs replacing | 3 | open |
The query plan is the same as before except that each resulting row is checked against a filter condition and any rows with a non-null value for the custom field are discarded.
Nested Loop Left Join (cost=0.29..97.73 rows=1 width=548)
Join Filter: (issue.id = date_attribute.issue)
Filter: (custom1 IS NULL)
-> Index Scan using issue_project_num_key on issue (cost=0.13..8.15 rows=1 width=540)
Index Cond: (project = '35e9b60a-d4d0-47ce-b9bd-af0a961ea65c'::uuid)
-> GroupAggregate (cost=0.15..85.08 rows=200 width=24)
Group Key: date_attribute.issue
-> Index Scan using date_attribute_pkey on date_attribute (cost=0.15..67.20 rows=1270 width=36)
Retrieving a complete set of results over the two queries will result in the database fetching issues with the attribute defined twice (filtering the duplicates out in the second query). In the worst case, where all issues do have the attribute defined, that doubles the cost.
You also have to be very careful when implementing pagination. Your API needs to switch seamlessly from one query to the next as the caller paginates through. The second query has the problem that it might have to scan through all the issues in the project before finding enough matching rows to fill a page.
One of the main reasons for using pagination is to avoid long running database queries and the resulting long tail API response times. If you’re dealing with truly large collections you may need to limit the complexity of each query. For example, you could use something like num > 100 AND num < 10100 LIMIT 100 as your pagination condition. This ensures that the query will scan at most 10000 rows as well as returning at most 100 results.
Conclusion
Well, we did it. Per project custom fields, with sorting on any field, still scaling as O(nlogn) when paginating over the complete set of issues. Doesn’t feel great though, does it?
- That O(nlogn) scaling comes with a really big constant factor. Make sure you benchmark to see how big a collection you need before it’s worth it.
- Those queries are getting complex. Plus you have to dynamically build them based on the attribute definitions for each project.
- It’s annoying that you need an extra join for each attribute type.
- It’s really annoying how much extra work and care is needed to sort on a custom field.
- The secondary sort for duplicate custom field values is on issue id, which is a UUID. To the end user, they might as well be in random order.
Can’t we do better than this? Well, maybe we can. But first I’ll need to lure you over to the dark side. Join me next time when we look at how we could Denormalize the database.